
Deduplicating rows
You can use the Remove duplicate rows function to easily delete all the rows that are exact duplicates and keep only one in your dataset.
Duplicated information can be introduced in spreadsheets because of human error, like a bad copy and paste for example, as well as automated operations. In this example, you received a dataset containing customer information, where all the rows are systematically duplicated.
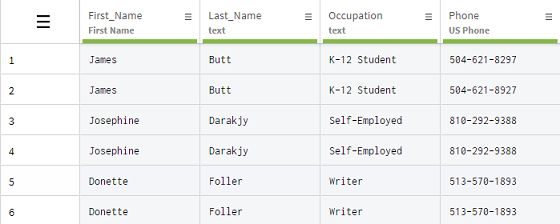
You will use the Remove duplicate rows function to easily clean your dataset.
Procedure
-
Point your mouse over the Remove duplicate rows function
and click the eye icon to preview its effects.
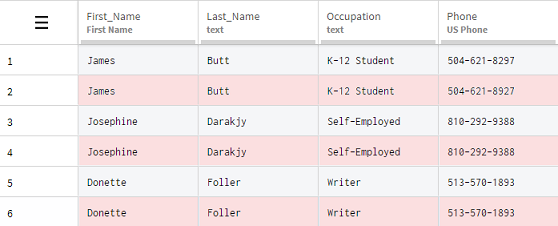
Results
All the duplicated information has been removed in one simple action, leaving you with only one correct occurrence of each row in your dataset.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!