
Talend Data Preparationのアーキテクチャー
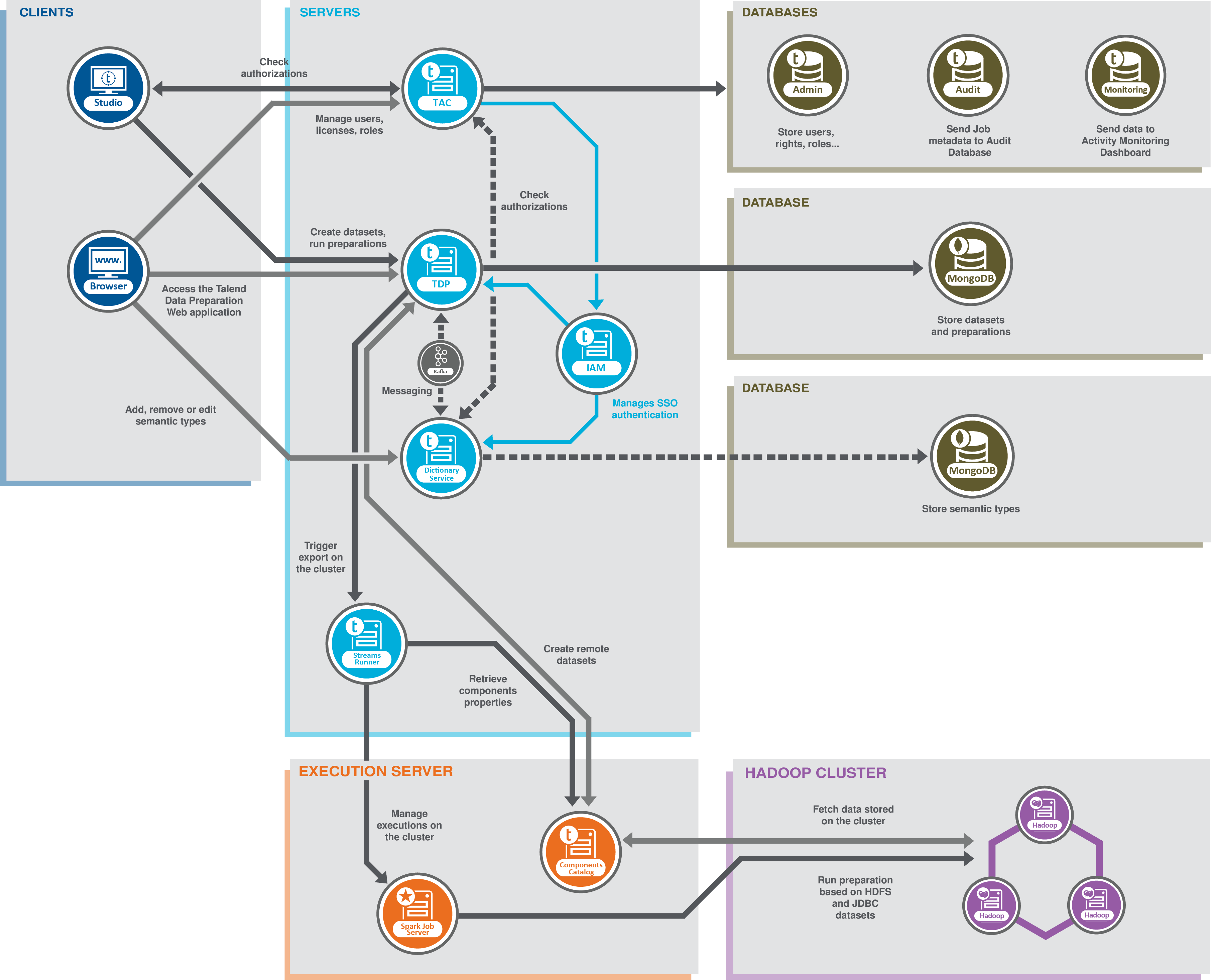
5種類の機能ブロックが定義されています。
-
クライアントブロックには、WebブラウザーとStudio Talendがあります。
WebブラウザーからTalend Data PreparationWebアプリケーションにアクセスします。ここでは、ローカルファイルやその他のソースからデータをインポートし、このデータに新しいプレパレーションを作成することによって、クレンジングやエンリッチ化を行います。また、必要に応じてTalend Dictionary Serviceサーバーにアクセスして、Webアプリケーションのデータに使用されるセマンティックタイプを追加、削除、編集できます。詳細は、セマンティックタイプライブラリーをエンリッチ化 (英語のみ)をご覧ください。
Studio Talendでは、tDatasetInput、tDatasetOutput、tDataprepRunの各コンポーネントを使用することで、Talend Data Preparationの機能を活用できます。さまざまなデータセットからデータセットを作成してTalend Data Preparationにエクスポートしたり、データ統合ジョブまたはSparkジョブでプレパレーションを直接利用したりできます。
-
サーバーブロックには、Talend Administration Centerに接続されたTalend Data Preparationアプリケーションサーバーが含まれており、必要に応じてTalend Dictionary ServiceサーバーとStreams Runnerサーバーも含まれます。このブロックには、Talend Data PreparationとTalend Dictionary Service間の内部メッセージング用に使用されるKafkaサーバーも含まれます。Talend Identity and Access Managementサービスは、シングルサインオンを有効にするために使用します。
管理者はTalend Administration Centerを使ってライセンス、ユーザー、ロールを管理できます。事前定義済みのロールを1つ以上ユーザーに割り当てると、Talend Data Preparationでアクセスや操作を実行するための特定の権限がユーザーに付与されます。Talend Administration Centerからは、Studio Talendで設計されたジョブを実行したり、ライブデータセット機能を使ってTalend Data Preparationでデータセットを直接取得したりすることもできます。
ビッグデータのコンテキストでは、クラスターからデータセットをインポートし、このフレームワーク上でBeamを使用して直接プレパレーションを実行するために、必要に応じて(Hadoopクラスターでの実行管理をロールとする)Streams Runnerサービスを使って、Spark Job Serverへのアクセスをトリガーします。
Talend Data Preparationでデータを開いた時に、必要ならTalend Dictionary Serviceを使って、データの各カラムに適用されているセマンティックカテゴリーを追加、削除、変更できます。
- Databases (データベース)ブロックにはTalend Administration CenterとMongoDB データベースで使用されるデータベースが含まれます。
管理データベースは、ユーザーのアカウントと権限を管理するために使用します。監査データベースは、Studio Talendで実施されたジョブのさまざまな側面を評価するために使用し、モニタリングデータベースは、技術的プロセスとサービス呼び出しの実行を監視するために使用します。
MongoDBデータベースは、すべてのデータセットとプレパレーション、およびアプリケーションのデータ検証に使うセマンティックタイプを保存するために使用します。コンピューターに直接保存されるものは何もありません。 -
実行サーバーブロックには、Hadoopクラスター上で実行されるエクスポートの管理に使用するSpark Job Server、およびComponents Catalogがあります。
Components Catalogサービスにより、各種データセットに保存されたデータをインポートしたり、Talend Data Preparationで直接リモートデータセットを作成したりできます。
- Hadoopクラスターブロックでは、ビッグデータのコンテキストでTalend Data Preparationを使って、HDFSまたはJDBCからインポートされたデータに対するプレパレーションを処理できます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。