
How a Talend Job for Apache Spark works
Depending on which framework you select for the Spark Job you are creating, this Talend Spark Job implements the Spark Streaming framework or the Spark framework when generating its code.
A Talend Spark Job can be run in any of the following modes:
-
Local: Talend Studio builds the Spark environment in itself at runtime to run the Job locally in Talend Studio. With this mode, each processor of the local machine is used as a Spark worker to perform the computations. This mode requires minimum parameters to be set in this configuration view.
Note this local machine is the machine in which the Job is actually run.
-
Standalone: Talend Studio connects to a Spark-enabled cluster to run the Job from this cluster.
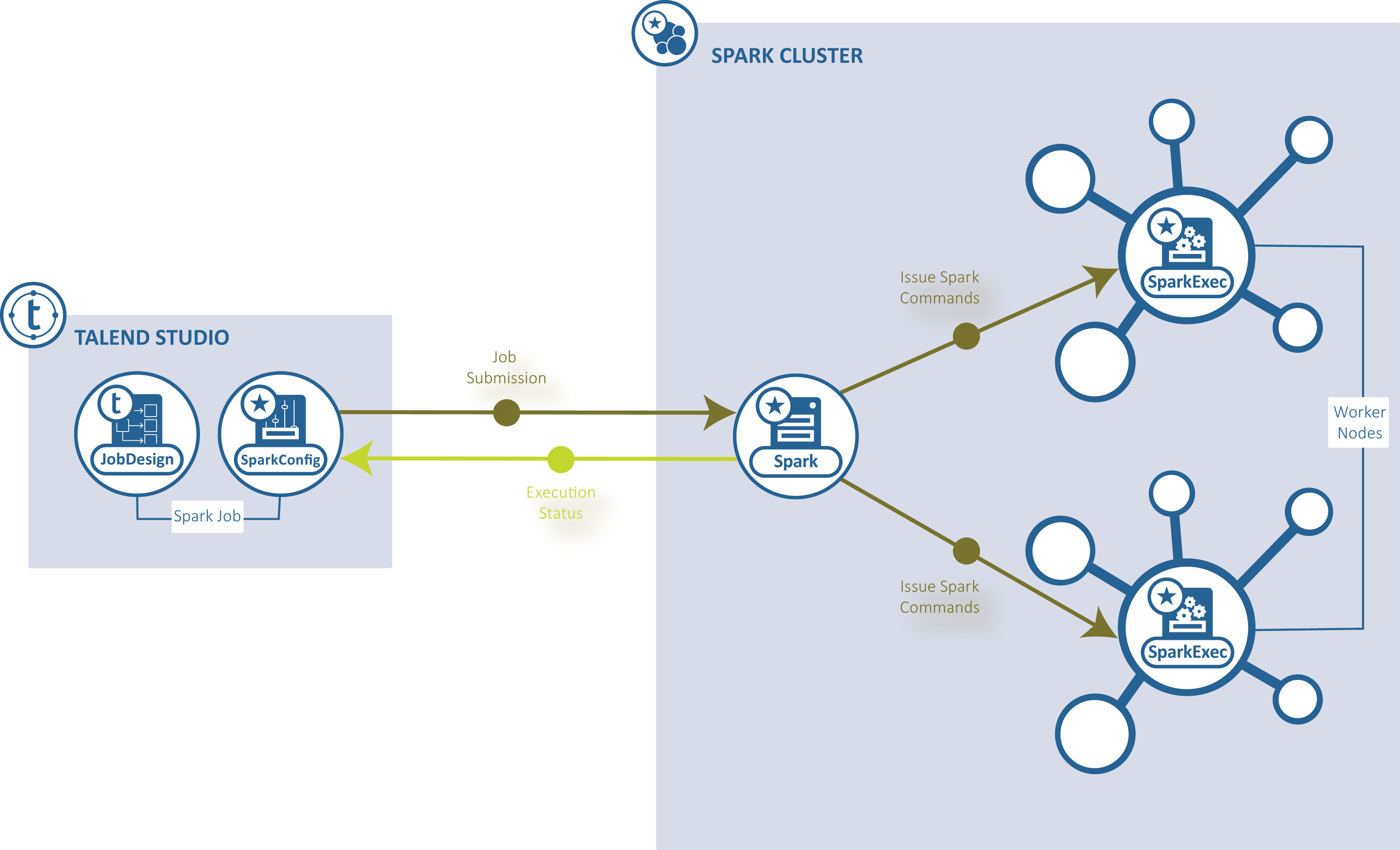
-
YARN client: Talend Studio runs the Spark driver to orchestrate how the Job should be performed and then send the orchestration to the YARN service of a given Hadoop cluster so that the Resource Manager of this YARN service requests execution resources accordingly.
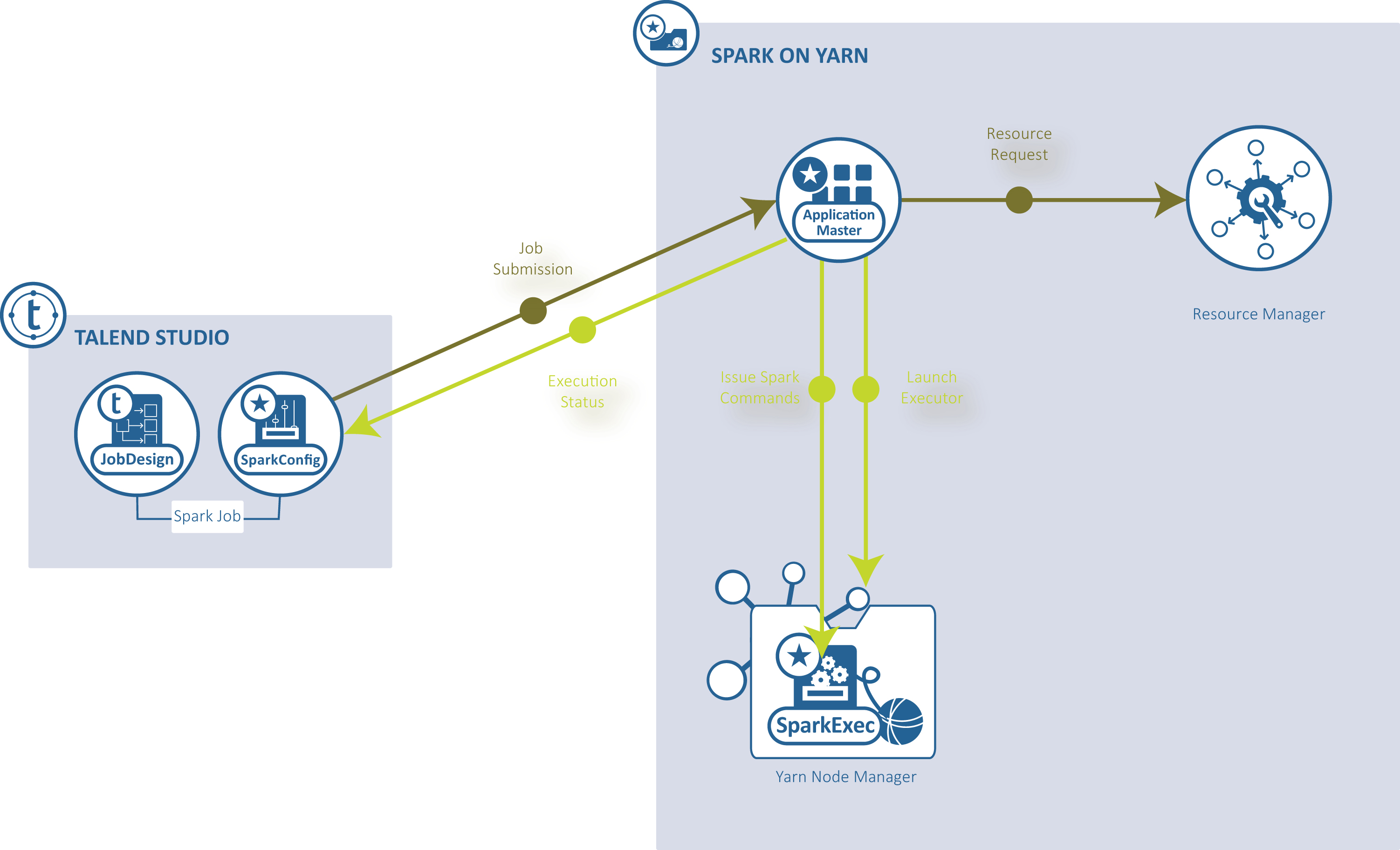
-
YARN cluster: Talend Studio submits Jobs to and collects the execution information of your Job from YARN and ApplicationMaster. The Spark driver runs on the cluster and can run independently from Talend Studio.
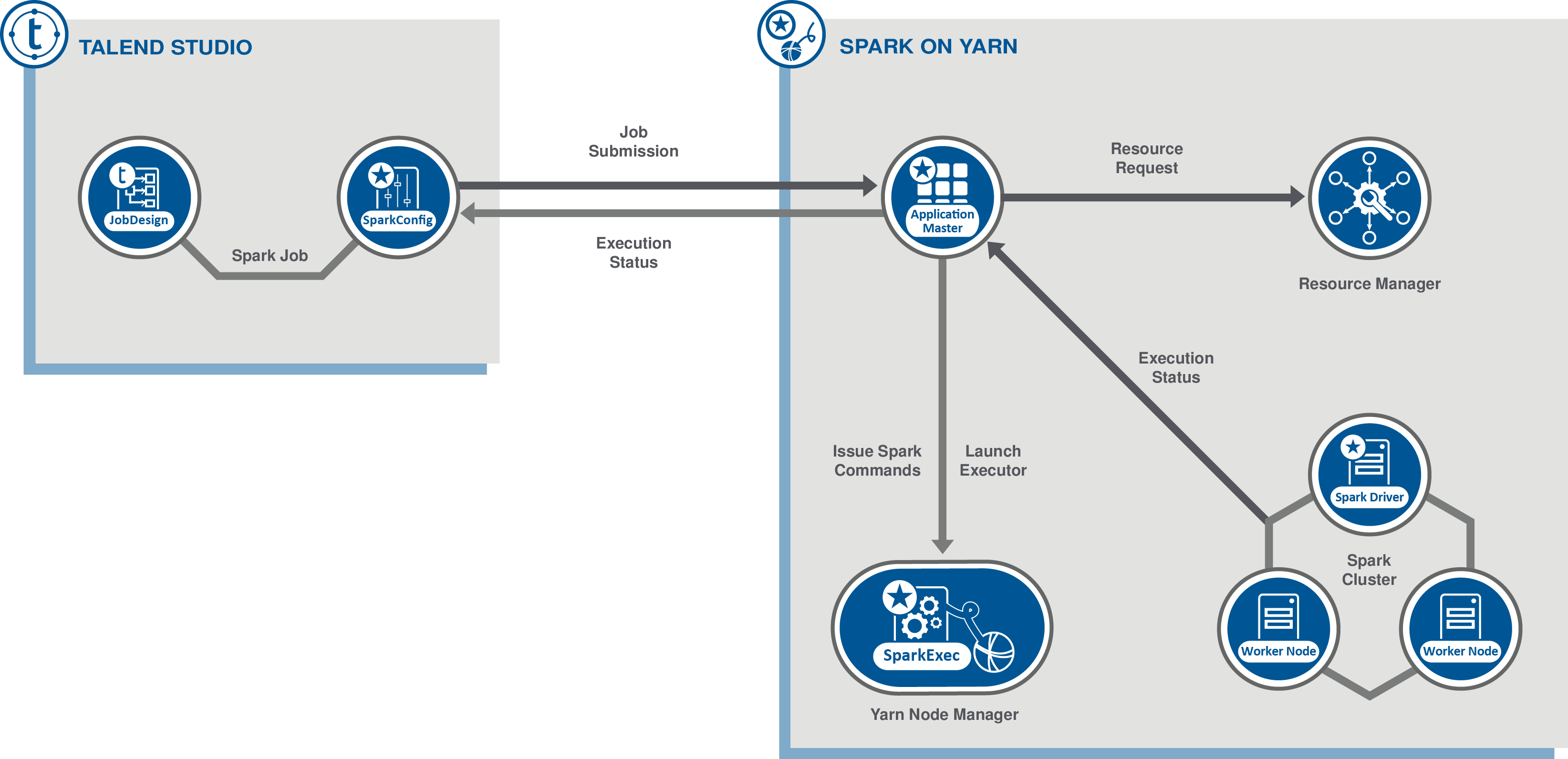
In Talend Studio, you design a Spark Job using the dedicated Spark components and configure the connection to the cluster to be used. At runtime, this configuration allows Talend Studio to directly communicate with the cluster to perform the following operations:
-
submit the Spark Job to the Master server in the Standalone mode or to the ApplicationMaster server in the Yarn client mode or the Yarn cluster mode of the cluster being used
-
and copy the related Job resources to the distributed file system of the same cluster. The cluster then completes the rest of the execution such as initializing the Job, generating Job ID and sending the execution progress information and the result back to Talend Studio.
Note that a Talend Spark Job is not equivalent to a Spark job explained in the Spark documentation from Apache. A Talend Spark Job generates one or several Spark jobs in terms of Apache Spark, depending on the way you design the Talend Job in the workspace of Talend Studio. For more information about what is a Spark job, see the glossary from the official Apache Spark documentation.
Each component in the Talend Spark Job knows how to generate the specific tasks to accomplish its mission (classes in the generated code), and how to join all the tasks together to form the Job. Each connection between components generates a given structure (an Avro record) that can contain data, and is compatible with Spark serialization. Components are optimized for their specific tasks. At runtime, these generated classes are shipped to the nodes to execute on data, the structures contain the data and are also shipped between nodes during shuffle phases, and the Talend Job itself coordinates the generated Spark jobs.
When you run the Job, some statistics information is displayed in the design workspace of the Job to indicate the progress of the Spark computations coordinated by the Job.
The following image presents an example of a Talend Spark Batch Job, in which the statistics information is displayed in green:
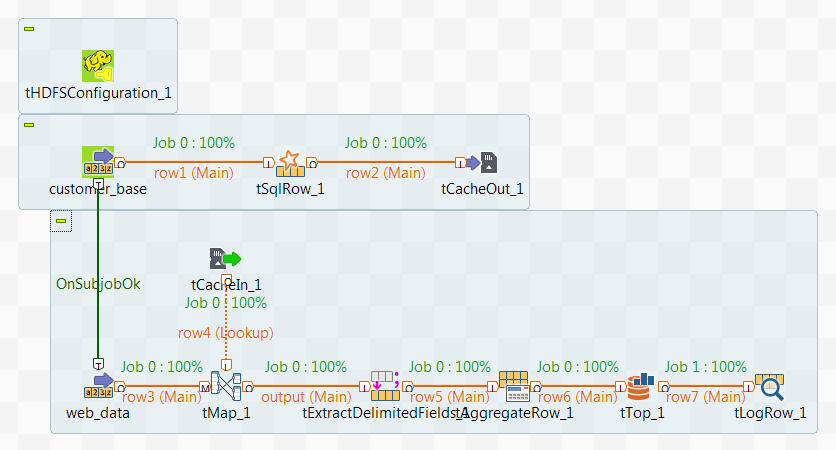
In this example, two Spark jobs, job 0 and job 1, are created and as you can read, are both 100% completed.
The execution information of a Talend Spark Job is logged by the HistoryServer service of the cluster be used. You can consult the web console of the service for that information. The name of the Job in the console is automatically constructed to be ProjectName_JobName_JobVersion, for example, LOCALPROJECT_wordcount_0.1.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!