
データフローの並列化を有効にする
Talend Studioでは、データフローの並列化とは、パフォーマンスを向上させるため、サブジョブの入力データフローを並列プロセスに分割し、同時に実行することを意味します。プロセスは常に同一マシンで実行されます。
このタイプの並列化は、平台ソリューションまたはビッグデータソリューションの1つにサブスクライブしている場合に限られます。
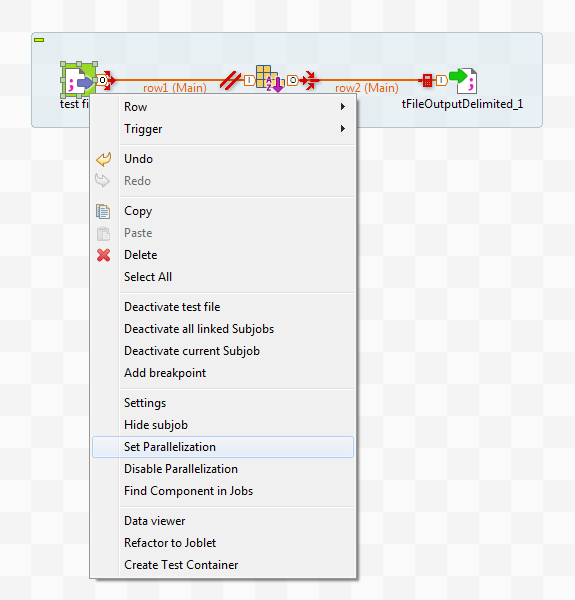
専用のコンポーネントを使用するか、ジョブのコンテキストメニューから[Set parallelization] (並列化の設定)オプションを設定して、このタイプの並列実行を実装できます。
専用コンポーネントとは、tPartitioner、tCollector、tRecollector、およびtDepartitionerのことです。
これ以降のセクションでは、[Set parallelization] (並列化の設定)オプションの使用方法および[Row] (行)接続に関連した縦に並んだタブの[Parallelization] (並列化)の使用方法について説明しています。
並列化の有効化または無効化は1回のクリックで設定でき、Talend Studioによりジョブ全体での実装が自動化されます。
並列化の実装には、次のような4つのキーステップが必要になります。
- 分割(
![[Partition] (分割)](/ja-JP/studio-user-guide/8.0/Content/Resources/images/auto_parallelization-partitioner.png) ): このステップでは、Talend Studioが入力レコードを特定数のスレッドに分割します。
): このステップでは、Talend Studioが入力レコードを特定数のスレッドに分割します。 - 収集(
![[Collect] (収集)](/ja-JP/studio-user-guide/8.0/Content/Resources/images/auto_parallelization-collector.png) ): このステップでは、Talend Studioが分割済みのスレッドを収集し、特定のコンポーネントに送って処理します。
): このステップでは、Talend Studioが分割済みのスレッドを収集し、特定のコンポーネントに送って処理します。 - 分割解除(
![[Departition] (分割解除)](/ja-JP/studio-user-guide/8.0/Content/Resources/images/auto_parallelization-departitioner.png) ): このステップでは、Talend Studioが分割済みスレッドの並列実行の結果をグルーピングします。
): このステップでは、Talend Studioが分割済みスレッドの並列実行の結果をグルーピングします。 - 再収集(
![[Recollect] (最終週)](/ja-JP/studio-user-guide/8.0/Content/Resources/images/auto_parallelization-recollector.png) ): このステップでは、Talend Studioがグルーピングされた実行結果を取得し、特定のコンポーネントに出力します。
): このステップでは、Talend Studioがグルーピングされた実行結果を取得し、特定のコンポーネントに出力します。
自動実装が終わると、コンポーネント間の該当する接続をクリックして、デフォルト設定を変更できます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。