
Hiveデータベースへの接続を作成
手順
-
[Next] (次へ)をクリックして次の手順に進みます。ここでは、Hiveの接続情報を入力します。このうち、[DB Type] (DBの種類)、[Hadoop cluster] (Hadoopクラスター)、[Distribution] (ディストリビューション)、[Version] (バージョン)、[Server] (サーバー)、[NameNode URL] (ネームノードURL)、[JobTracker URL] (ジョブトラッカーURL)には、前の手順で選択したHadoop接続から継承されたプロパティが自動的に入力されます。
[Hadoop cluster] (Hadoopクラスター)リストから[None] (なし)を選択すると、手動モードに切り替わり、継承されたプロパティが破棄されるので、すべてのプロパティを手動で入力しなければなりません。作成された接続は、[Db connection] (データベース接続)ノードの下だけに表示されます。
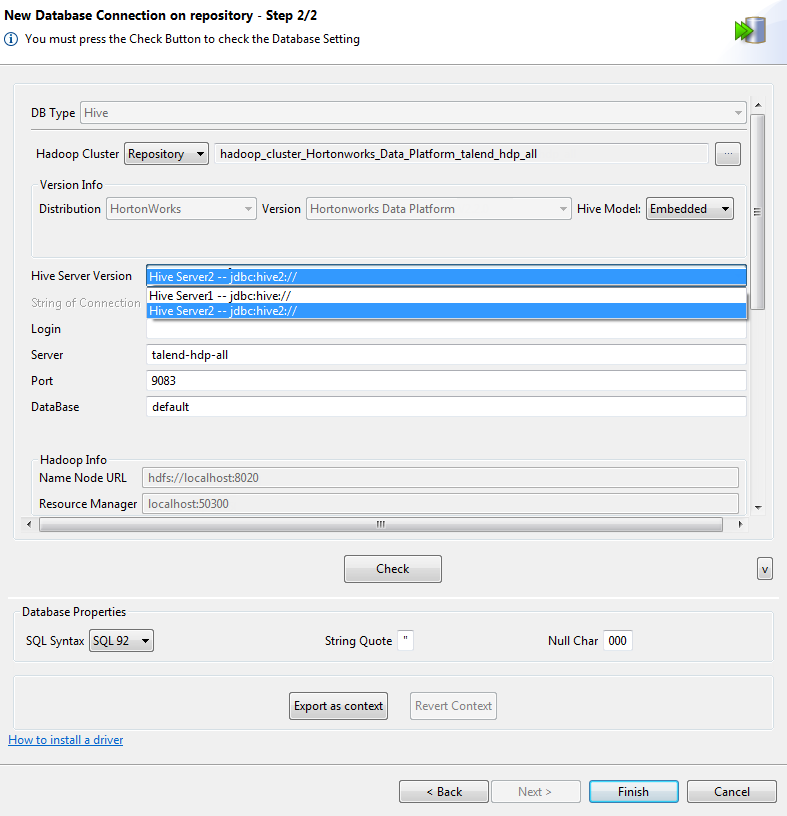 設定するプロパティは、接続しているHadoopのディストリビューションによって異なります。
設定するプロパティは、接続しているHadoopのディストリビューションによって異なります。 -
選択したHiveモデルに応じて表示されるフィールドに情報を入力します。
[Database] (データベース)フィールドを空欄にした場合は、[Standalone] (スタンドアロン)モデルを選択すると、defaultのHiveデータベースへの接続のみが有効になります。

-
Kerberosセキュリティを実行しているHadoopディストリビューションにアクセスする場合は、[Use Kerberos authentication] (Kerberos認証を使用)チェックボックスをオンにします。次に、[Hive principal] (Hiveプリンシパル)フィールドが表示されたら、Kerberosのプリンシパル名を入力します。
ログインにkeytabファイルが必要な場合は、[Use a keytab to authenticate] (認証にkeytabを使用)チェックボックスをオンにし、使用するプリンシパルを[Principal] (プリンシパル)フィールドに入力し、keytabファイルへのパスを[Keytab]フィールドに入力します。
keytabファイルには、Kerberosのプリンシパルと暗号化されたキーのペアが含まれています。keytabが有効なジョブは、プリンシパルに任命されたユーザーでなくても実行できますが、使用するkeytabファイルの読み取り権限が必要です。たとえば、user1というユーザー名でジョブを実行し、使用するプリンシパルがguestの場合、user1に使用するkeytabファイルの読み取り権限があることをご確認ください。
How to use Kerberos in Talend Studioで説明されている手順に従って、Kerberosが正しく設定されたかどうか確認します。
例

-
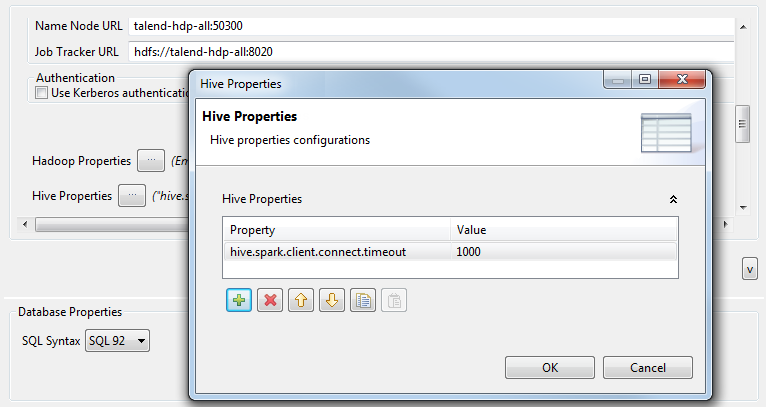
使用するHadoopまたはHiveディストリビューションの設定をカスタマイズする必要がある場合は、[Hadoop properties] (Hadoopのプロパティ)または[Hive Properties] (Hiveプロパティ)の横の[...]ボタンをクリックして対応するプロパティテーブルを開き、カスタマイズするプロパティを追加します。その後、実行時にTalend StudioがHadoopのエンジンに使用するデフォルトのプロパティが、カスタマイズした設定に上書きされます。
Hadoopのプロパティの詳細は、Apache Hadoopに関するドキュメンテーションか、使用するHadoopディストリビューションのドキュメンテーションをご覧ください。たとえば、このページにはデフォルトのHadoopプロパティがいくつか記載されています。Hiveのプロパティの詳細は、Hiveに関するApacheドキュメンテーションをご覧ください。たとえば、このページにはHiveの設定プロパティがいくつか記述されています。これらのプロパティテーブルの活用方法の詳細は、再利用可能なHadoopのプロパティの設定をご覧ください。
-
[Finish] (終了)をクリックして変更を確定し、ウィザードを閉じます。
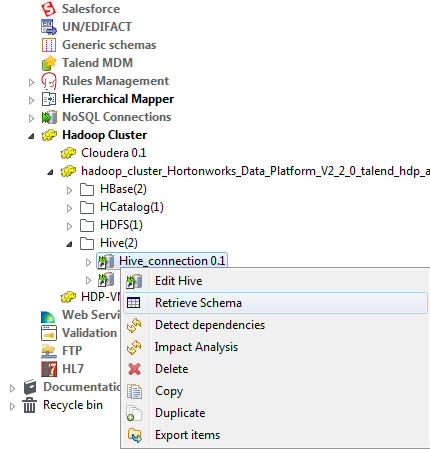
特定のHiveデータベースに作成した接続は、[Repository] (リポジトリー)ツリービューの[DB Connections] (データベース接続)フォルダーの下に表示されます。この接続には4つのサブフォルダーがあり、そのうちの[Table schema] (テーブルスキーマ)には、この接続に関連するすべてのスキーマをグルーピングできます。
 環境コンテキストを使用してこの接続のパラメーターを定義する必要がある場合は、[Export as context] (コンテキストとしてエクスポート)ボタンをクリックして対応するウィザードを開き、以下のオプションから選択します。
環境コンテキストを使用してこの接続のパラメーターを定義する必要がある場合は、[Export as context] (コンテキストとしてエクスポート)ボタンをクリックして対応するウィザードを開き、以下のオプションから選択します。-
[Create a new repository context] (新しいリポジトリーコンテキストを作成): 現在のHadoop接続からこの環境コンテキストを作成します。つまり、ウィザードで設定するパラメーターは、これらのパラメーターに設定した値と共にコンテキスト変数として取られます。
-
[Reuse an existing repository context] (既存のリポジトリーコンテキストを再利用): 特定の環境コンテキストの変数を使用して現在の接続を設定します。
この[Export as context] (コンテキストとしてエクスポート)機能の使い方に関するステップバイステップの説明は、メタデータのコンテキストとしてエクスポート、およびコンテキストパラメーターを再利用して接続を設定をご覧ください。
-
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。