
Big Data: Neue Funktionen
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Unterstützung für Spark Universal | Sie können Ihre Spark-Jobs jetzt unter Rückgriff auf Spark Universal mit Spark 2.4.x oder 3.0.x sowohl im lokalen Modus (Local) als auch im Modus Yarn cluster (Yarn-Cluster) ausführen. Spark Universal ist ein Mechanismus, der die Kompatibilität von Talend Studio mit allen für eine bestimmte Spark-Version verfügbaren Big-Data-Distributionen gewährleistet. Dazu wird lediglich eine JAR-Datei mit einer Hadoop-Konfiguration verwendet, die alle erforderlichen Informationen für den Aufbau einer Verbindung zu dem in Yarn cluster (Yarn-Cluster) angegebenen Cluster enthält. Spark Universal stattet Sie mit größerer Flexibilität aus, da Sie ganz nach Bedarf zwischen den verschiedenen Spark-Modi, Distributionen oder Umgebungen umschalten können. Die Konfiguration der Spark Universal-Verbindung erfolgt entweder in der Ansicht Spark configuration (Spark-Konfiguration) Ihrer Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung) der Baumstrukturansicht Repository:
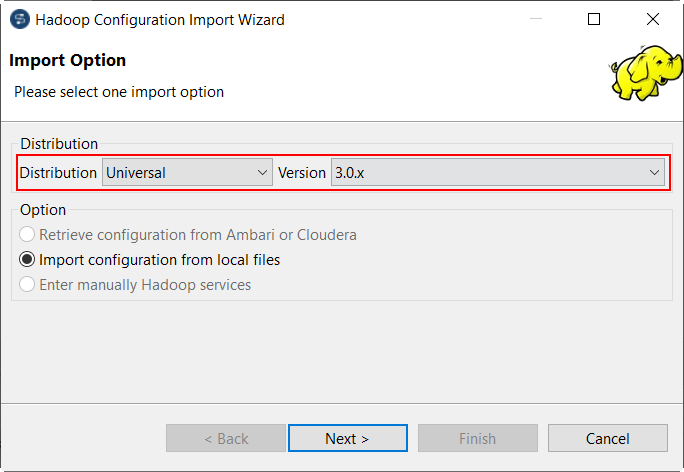
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für Kubernetes mit Spark Universal 3.1.x | Sie können Ihre Spark-Jobs jetzt unter Rückgriff auf Spark Universal mit Spark 3.1.x im Kubernetes-Modus ausführen. Die Konfiguration der Spark Universal-Verbindung mit Kubernetes erfolgt entweder in der Ansicht Spark configuration (Spark-Konfiguration) Ihrer Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung) der Baumstrukturansicht Repository:
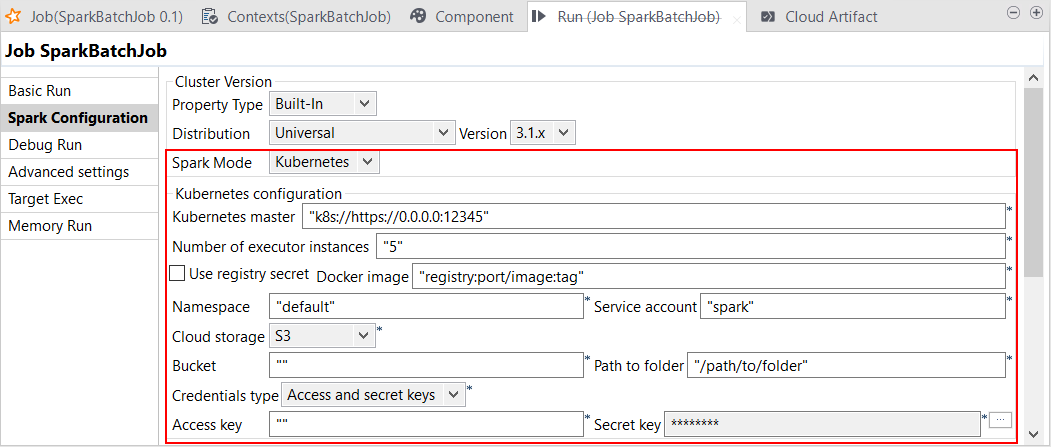
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung dynamischer Schemas in Spark Batch-Komponenten | Sie können jetzt mit den folgenden Komponenten dynamische Schemas in Ihren Spark-Jobs verwenden:
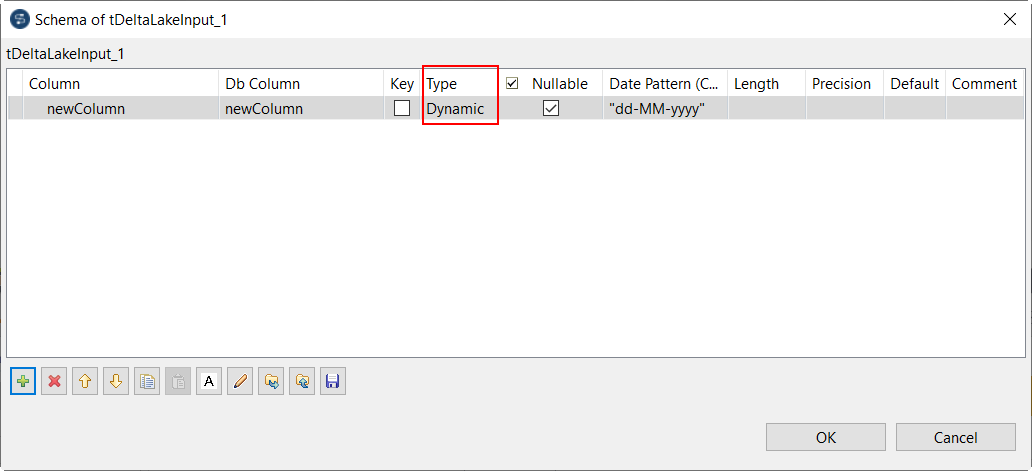
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!