
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Unterstützung für das Iceberg-Tabellenformat in tHiveCreateTable in Standard-Jobs | Sie können jetzt mit tHiveCreateTable Iceberg-Tabellen in Standard-Jobs erstellen, entweder unter Verwendung von Cloudera- oder von Amazon EMR-Distributionen. Iceberg-Tabellen ermöglichen Ihnen die Verwendung unterschiedlicher Dateiformate, wie z. B. Parquet, ORC und Avro mit Cloudera-Distributionen. Mit Amazon EMR-Distributionen ist nur das Parquet-Format zulässig. 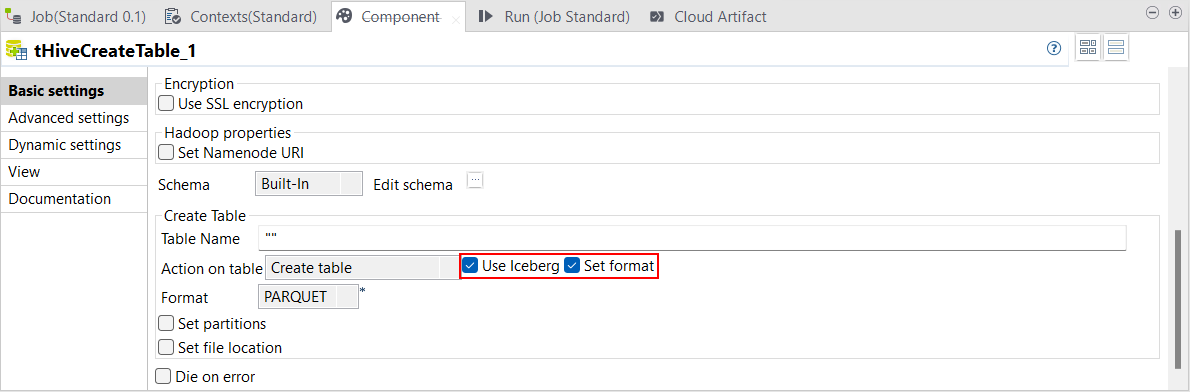
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Neue tHBaseNamespace-Komponente zur Erstellung von Namespaces für HBase-Tabellen in Standard-Jobs | In Ihren Standard-Jobs in Talend Studio ist jetzt die neue Komponente tHBaseNamespace verfügbar. Diese Komponente ermöglicht Ihnen die Erstellung von Namespaces für HBase-Tabellen.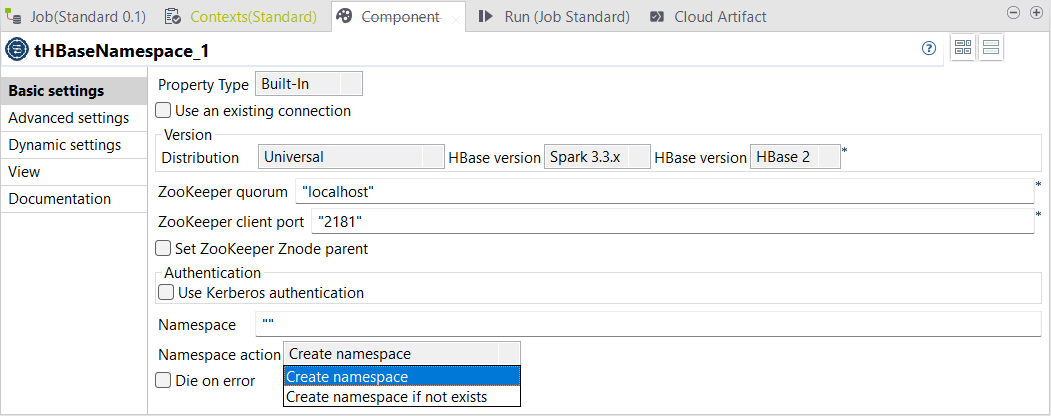
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für HDInsight 5.0 mit Spark Universal 3.1.x | Sie können Ihre Spark Batch- und Streaming-Jobs jetzt in HDInsight mit Spark Universal 3.1.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung) mit ADLS Gen2 Storage oder Azure Storage. Wenn Sie diesen Modus auswählen, ist Talend Studio mit der Version HDInsight 5.0 kompatibel. Sie müssen die Log4j-Komponenten deaktivieren, um die Spark-Jobs in HDInsight ausführen zu können. Rufen Sie dazu auf und deaktivieren Sie das Kontrollkästchen Activate log4j in components (log4j in Komponenten aktivieren). 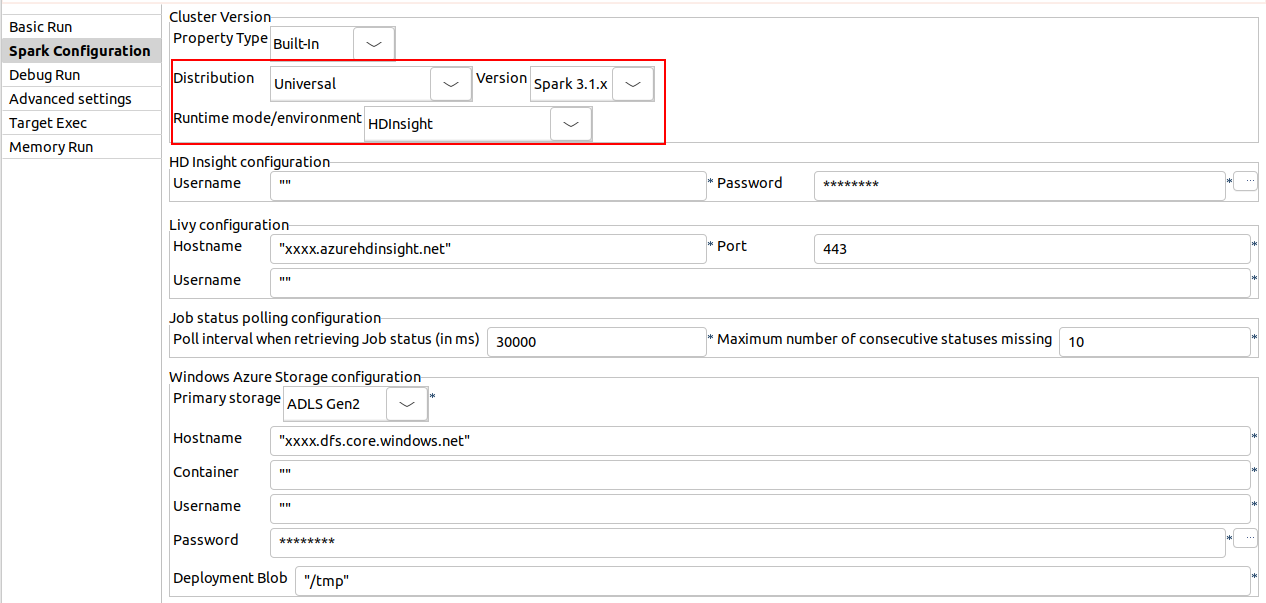
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für AWS EMR Serverless 6.6.0 mit Spark Universal 3.2.x und 3.3.x | Sie können Ihre Spark Batch-Jobs jetzt in AWS EMR Serverless mit Spark Universal 3.2.x und 3.3.x ausführen. Die entsprechende Konfiguration können Sie in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark Batch-Jobs vornehmen. Wenn Sie diesen Modus auswählen, ist Talend Studio mit der Version AWS EMR Serverless 6.6.0 kompatibel. 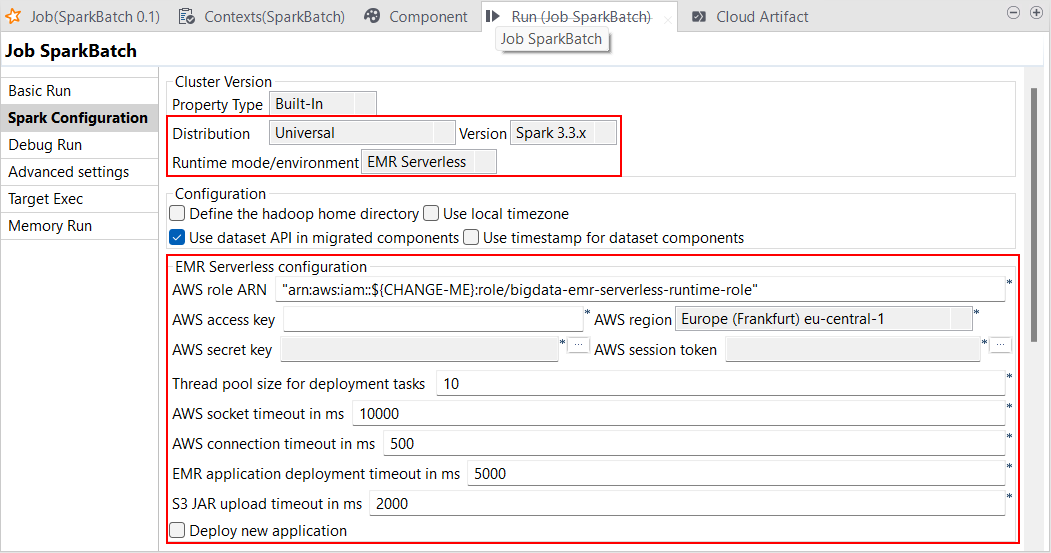
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!