
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Unterstützung für Spark Universal 3.4.x im lokalen Modus | Sie können Ihre Spark Batch- und Spark Streaming-Jobs jetzt unter Rückgriff auf Spark Universal mit Spark 3.4.x im lokalen Modus (Local) ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung).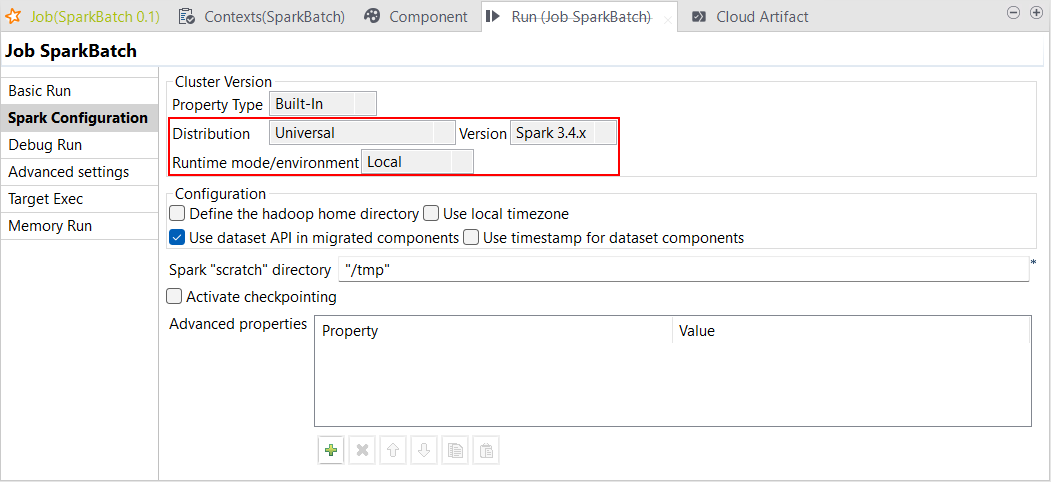
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für benutzerdefinierte Einstellungen in AWS EMR Serverless mit Spark Universal 3.2.x und 3.3.x in Spark Batch-Jobs | Sie können die Einstellungen für Ihre Spark Batch-Jobs in AWS EMR Serverless mit Spark Universal 3.2.x und 3.3.x jetzt bedarfsgerecht anpassen. Die entsprechende Konfiguration können Sie in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark Batch-Jobs vornehmen. Aktivieren Sie dazu das Kontrollkästchen Custom settings (Benutzerdefinierte Einstellungen). Mit diesem neuen Parameter können Sie jetzt sämtliche Einstellungen kontrollieren, einschließlich der vorinitialisierten Kapazität oder der Netzwerkverbindung beispielsweise. 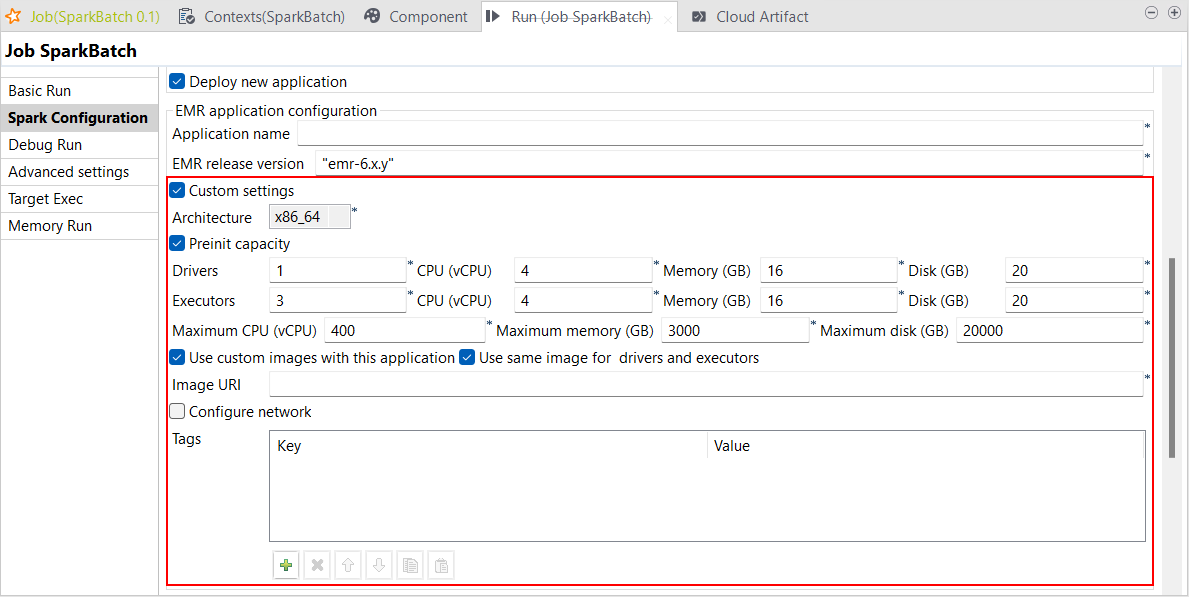
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für Dataproc ab Version 2.1 mit Spark Universal 3.3.x in Spark Batch-Jobs | Sie können Ihre Spark Batch-Jobs jetzt in Dataproc mit Spark Universal 3.3.x ausführen. Die entsprechende Konfiguration können Sie in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark Batch-Jobs vornehmen. Wenn Sie diesen Modus auswählen, ist Talend Studio mit Dataproc ab Version 2.1 kompatibel. 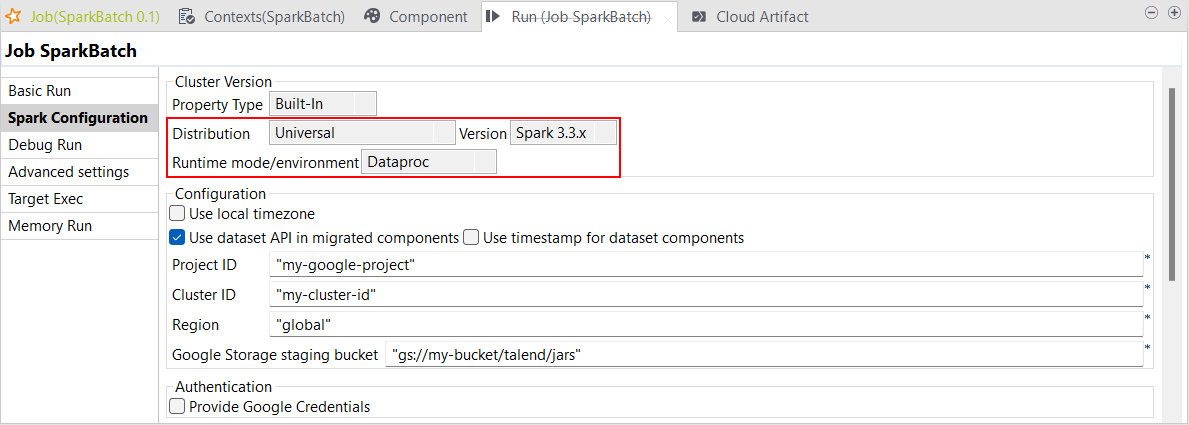
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für Dataproc ab Version 2.1 mit Spark Universal 3.3.x in Standard-Jobs | Standard-Jobs mit Hive-Komponenten unterstützen jetzt Dataproc ab Version 2.1 mit Spark Universal 3.3.x.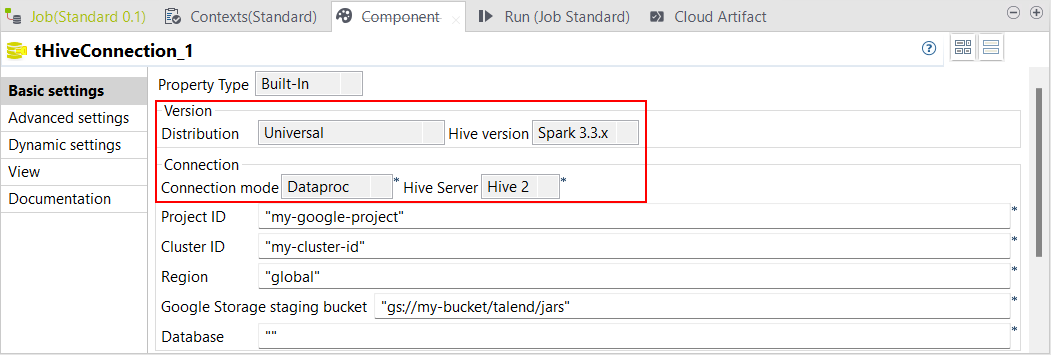
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für spark-submit-Skripte mit Universal 3.3.x in Spark Batch-Jobs | Der Modus Spark-submit scripts (spark-submit-Skripte) ermöglicht Ihnen die Nutzung eines HPE Ezmeral Data Fabric v9.1.x-Clusters zur Ausführung Ihrer Spark Batch-Jobs. Sie können diesen Modus auch mit anderen Clustern als HPE Data Fabric verwenden. Das ist darauf zurückzuführen, dass spark-submit-Skripte für einen Einsatz mit allen von Spark unterstützten Cluster-Managern entwickelt wurden (siehe die Informationen über Cluster-Manager in der Spark-Dokumentation). |
Alle abonnementbasierte Produkte von Talend mit Big Data |
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!