
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Unterstützung für den Standalone-Modus mit Spark Universal 3.4.x | Sie können Ihre Spark Batch- und Spark Streaming-Jobs jetzt unter Rückgriff auf Spark Universal mit Spark 3.4.x im Standalone-Modus ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Bei der Auswahl dieses Modus stellt Talend Studio eine Verbindung zu einem Spark-fähigen benutzerspezifischen Cluster für die Ausführung des Jobs ausgehend von diesem Cluster her. Mit der generellen Verfügbarkeit dieser Funktion wird HBase jetzt unterstützt. Beachten Sie, dass für Hive und Spark-Jobs mit Avro-Komponenten im Augenblick keine Unterstützung geboten wird. 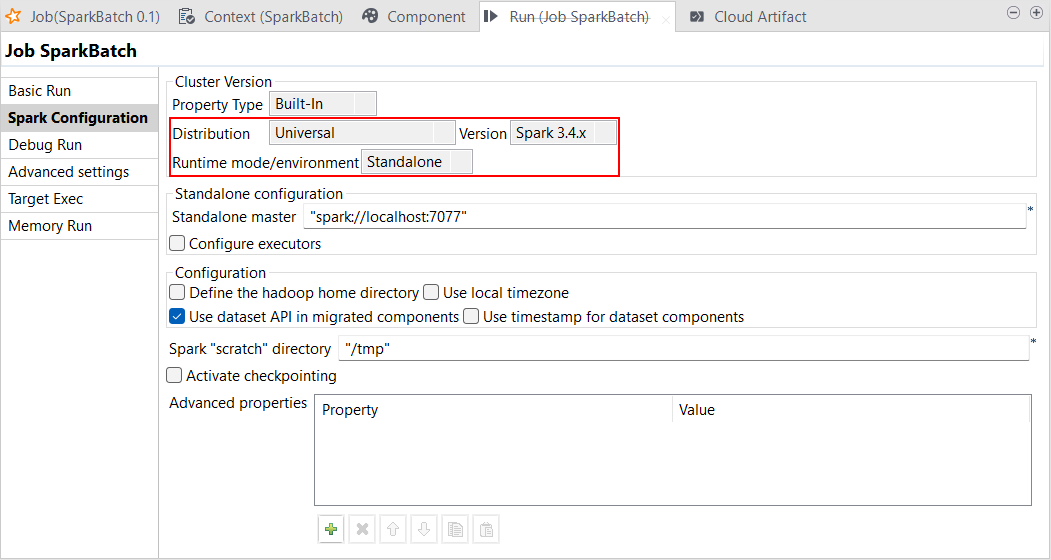 |
Alle abonnementbasierte Produkte von Talend mit Big Data |
| In tHBaseTable verfügbare neue Optionen | In der Ansicht Basic settings (Basiseinstellungen) von tHBaseTable sind jetzt neue Parameter verfügbar:
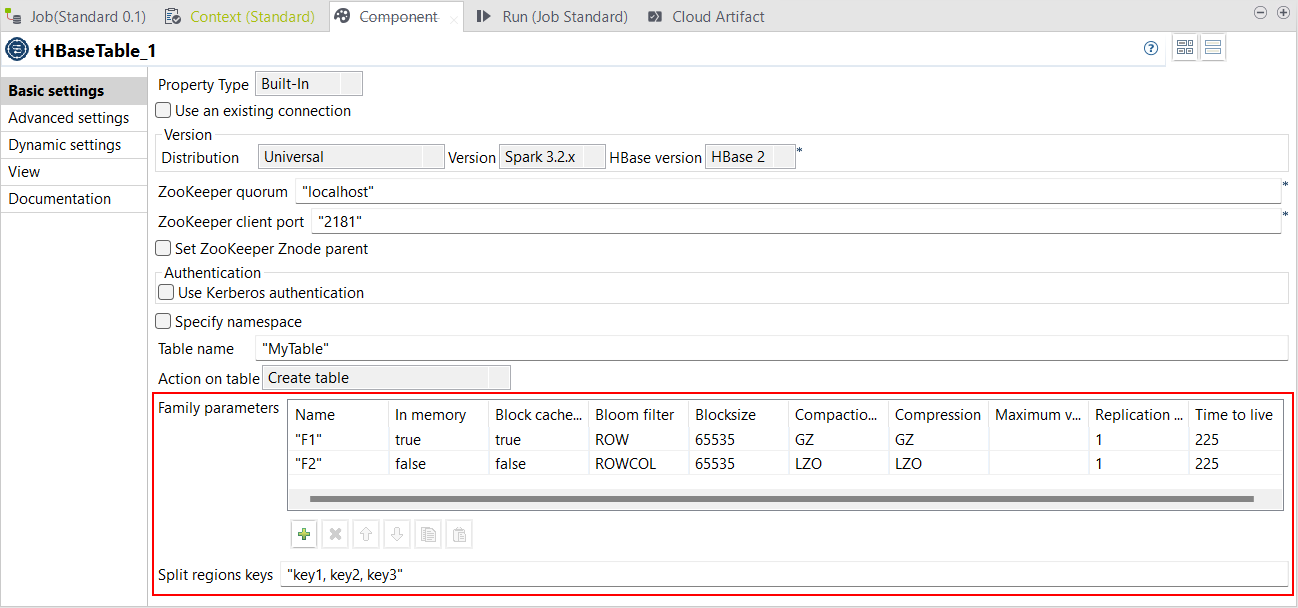 |
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für Databricks Runtime 13.x mit Spark Universal 3.4.x | Sie können Ihre Spark Batch- und Streaming-Jobs jetzt in jobbasierten wie auch in multifunktionalen Databricks-Clustern in Google Cloud Platform (GCP), AWS und Azure unter Rückgriff auf Spark Universal mit Spark 3.4.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Talend Studio mit Databricks 13.x kompatibel. 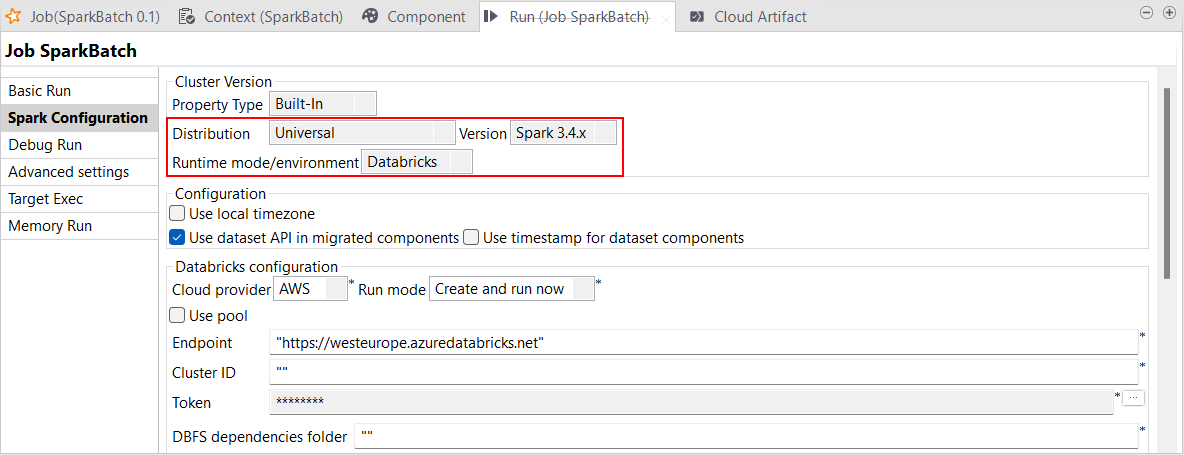 |
Alle abonnementbasierte Produkte von Talend mit Big Data |
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!