
Konzepte von Talend Cloud Pipeline Designer
Das folgende Diagramm und die nachstehenden Definitionen sollen Ihnen dabei helfen, die Hauptkonzepte von Talend Cloud Pipeline Designer zu verstehen.
- Moteur distant Gen2: Bei einer Moteur distant Gen2 handelt es sich um eine sichere Ausführungs-Engine, auf der Pipelines sicher ausgeführt werden können. Sie erhalten Kontrolle über Ihre Ausführungsumgebung und Ressourcen, da Sie die Engine in Ihrer eigenen Umgebung (Virtual Private Cloud oder On-Premise) erstellen und konfigurieren können.
Eine Moteur distant Gen2 stellt Folgendes sicher:
-
Datenverarbeitung in einer sicheren und geschützten Umgebung, da Talend nie Zugriff auf die Daten und Ressourcen Ihrer Pipelines erhält.
-
Optimale Leistung und Sicherheit durch erhöhte Datenlokalität anstelle der Übertragung umfangreicher Datenmengen zur Verarbeitung.
-
- Moteur Cloud pour le design: Die Cloud Engine ist ein integrierter „Runner“, der den Benutzern die Gestaltung von Pipelines erleichtert, da keine Verarbeitungs-Engines eingerichtet werden müssen. Mit dieser Engine können zwei Pipelines parallel ausgeführt werden. Für eine erweiterte Datenverarbeitung wird die Installation der sicheren Moteur distant Gen2 empfohlen.
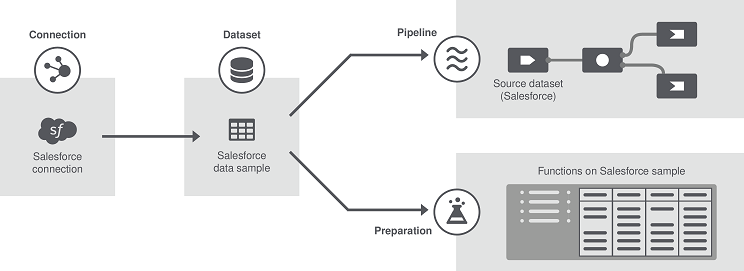
- Verbindung: Verbindungen sind Umgebungen oder Systeme, in denen Datensätze gespeichert werden, darunter Datenbanken, Dateisysteme, verteilte Systeme oder Plattformen usw. Die Verbindungsinformationen für diese Systeme müssen nur einmal erfasst werden, da sie wiederverwendbar sind.
- Datensatz: Datensätze sind Datensammlungen. Es kann sich um Datenbanktabellen, Dateinamen, Topics (Kafka), Dateipfade (HDFS) usw. handeln. Außerdem können Sie Testdatensätze erstellen, die Sie manuell eingeben und in einer Testverbindung speichern, und sogar lokale Dateien als Datensätze importieren. Mehrere Datensätze können mit demselben System (1:n-Konnektivität) verbunden und in wiederverwendbaren Verbindungen gespeichert werden.
- Pipeline: Pipelines bestehen aus einem Prozess (vergleichbar mit einem Talend-Job), der kontinuierlich nach eingehenden Daten sucht, sowie aus einer „Pipe“, also einer Leitung, über die Daten von einer Quelle, dem Datensatz, eingehen und an ein Ziel gesendet werden. Man unterscheidet zwischen verschiedenen Arten von Pipelines:
-
Batch-Pipelines oder „Bounded“ Pipelines, d. h. „begrenzte“ Pipelines. In diesem Fall werden die Daten erfasst und die Pipeline wird angehalten, sobald alle Daten verarbeitet wurden.
-
Streaming-Pipelines oder „Unbounded“ Pipelines, d. h. „nicht verbundene“ Pipelines. Diese Art von Pipeline liest kontinuierlich Daten und stellt den Betrieb nur ein, wenn Sie sie anhalten.
-
- Prozessor: Prozessoren sind Komponenten, die Sie Ihren Pipelines hinzufügen können, um eingehende Batches oder Streaming-Daten zu transformieren und die transformierten Daten dann an den nächsten Schritt in der Pipeline zu übergeben.
- Sample: Ihre Daten werden in Form eines Samples angezeigt, das aus den Metadaten der Datensätze abgerufen wird.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!