
Verwenden unterschiedlicher Verbindungszeichenfolgen bei der Ausführung mithilfe von Kontextvariablen
In diesem Szenario werden Kontextvariablen hinzugefügt, um die verbindungsspezifischen Anmeldedaten zu überschreiben und dadurch bei der Ausführung zwischen einer Vorproduktions- und Produktionsdatenbank umzuschalten.
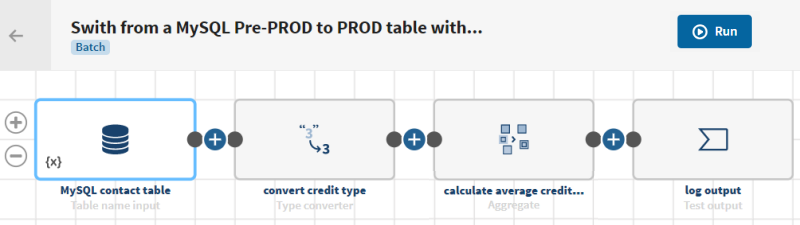
Vorbereitungen
-
Sie haben zuvor eine Verbindung zu dem System erstellt, in dem die Quelldaten gespeichert sind, in diesem Fall eine MySQL-Verbindung.
-
Sie haben zuvor den Datensatz hinzugefügt, der die Quelldaten enthält.
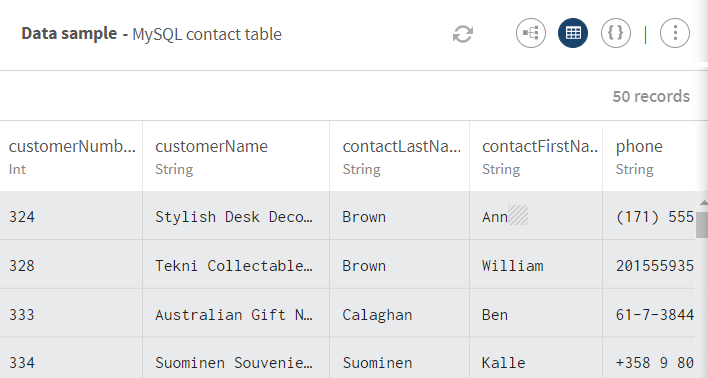
In diesem Beispiel handelt es sich um eine Tabelle mit Kontaktdaten, einschließlich Kundenkennungen, Namen, Adressen, Länder, Kreditlimits usw.
- Sie haben ebenfalls die Zielverbindung erstellt, in diesem Fall einen Testdatensatz, in dem die Ausgabelogs gespeichert werden sollen.
Prozedur
-
Klicken Sie auf ADD SOURCE (QUELLE HINZUFÜGEN), um ein Fenster zu öffnen, in dem Sie die Quelldaten auswählen können, in diesem Beispiel MySQL contact table (MySQL-Kontakttabelle). Im Vorschaufenster wird ein Sample Ihrer Daten angezeigt.
-
Klicken Sie auf
 und fügen Sie einen Prozessor des Typs Type converter (Typkonverter) zur Pipeline hinzu. Das Konfigurationsfenster wird geöffnet.
und fügen Sie einen Prozessor des Typs Type converter (Typkonverter) zur Pipeline hinzu. Das Konfigurationsfenster wird geöffnet.
-
Klicken Sie auf und fügen Sie einen Prozessor des Typs Aggregate (Aggregieren) zur Pipeline hinzu. Das Konfigurationsfenster wird geöffnet.
-
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
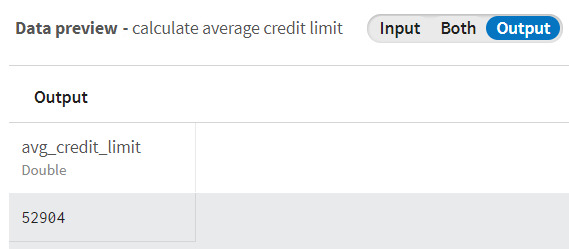
Die Datensätze mit den Kreditlimits wurden in den Typ Doppelwert (Double) konvertiert.
-
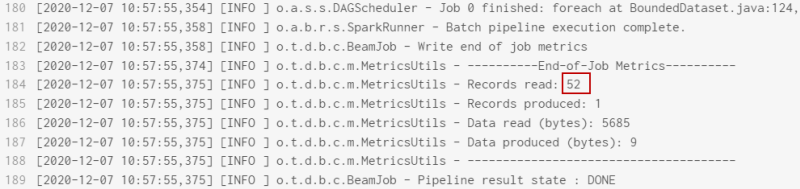
(Optional) Wenn Sie die Pipeline zu diesem Zeitpunkt ausführen, wird in den Logs Folgendes angegeben:
- Die Pipeline wurde erfolgreich ausgeführt, es wurden 52 Datensätze gelesen.
- In der Pipeline wurden keine Kontextvariablen festgelegt.

- Die Pipeline wurde erfolgreich ausgeführt, es wurden 52 Datensätze gelesen.
-
Kehren Sie zur Registerkarte Connection (Verbindung) der Quelle MySQL contact table (MySQL-Kontakttabelle) zurück, um eine andere Variable hinzuzufügen und zuzuweisen:
-
Klicken Sie auf das Symbol
 neben dem Parameter JDBC URL (JDBC-URL), um das Fenster [Add variable] (Variable hinzufügen) zu öffnen.
neben dem Parameter JDBC URL (JDBC-URL), um das Fenster [Add variable] (Variable hinzufügen) zu öffnen.
-
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
Nach der Zuweisung der Variablen wird das Symbol
 angezeigt, um darauf hinzuweisen, dass eine Variable in der Pipeline festgelegt wurde.
angezeigt, um darauf hinzuweisen, dass eine Variable in der Pipeline festgelegt wurde.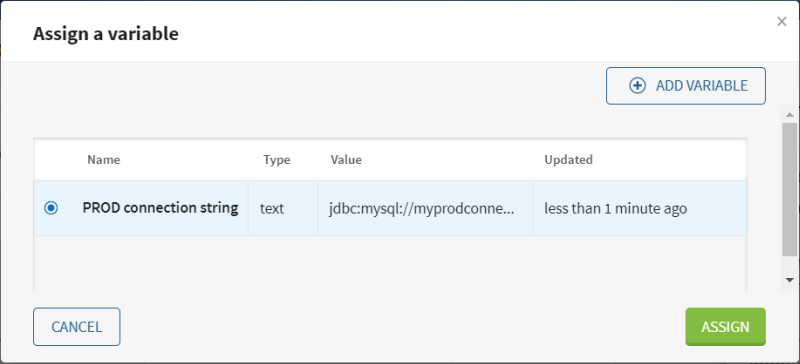
-
Klicken Sie auf das Symbol
Ergebnisse
- Den Ausführungslogs der Pipeline können Sie entnehmen, dass eine größere Anzahl an Datensätzen gelesen wurde (1153).
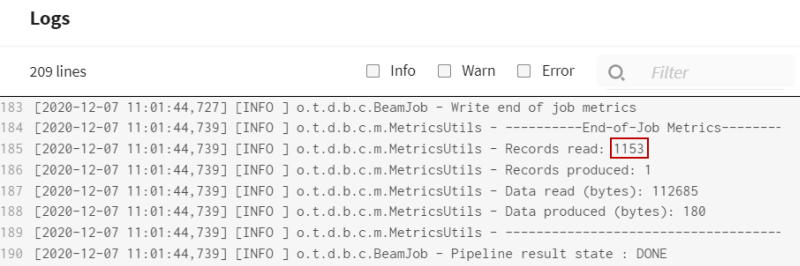
- Darüber hinaus wird der Wert der Kontextvariablen angegeben, die zum Abrufen der Daten aus der Produktionstabelle bei der Ausführung verwendet wurden.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!