
Setting up the connection to your Big Data platform
Setting up the connection to a given Big Data platform in the Repository allows you to avoid configuring that connection each time when you need to use the same platform.
The Big Data platform to be used in this example is a Databricks V5.4 cluster, along with Azure Data Lake Storage Gen2.
Before you begin
-
Ensure that your Spark cluster in Databricks has been properly created.
For further information, see Create Databricks workspace from Azure documentation.
- You have an Azure account.
- The storage account for Azure Data Lake Storage Gen2 has been properly created and you have the appropriate read and write permissions to it. For further information about how to create this kind of storage account, see Create a storage account with Azure Data Lake Storage Gen2 enabled from Azure documentation.
-
The Integration perspective is active.
About this task
Procedure
-
On the Configuration tab of your Databricks cluster
page, scroll down to the Spark tab at the bottom of the
page.
Example
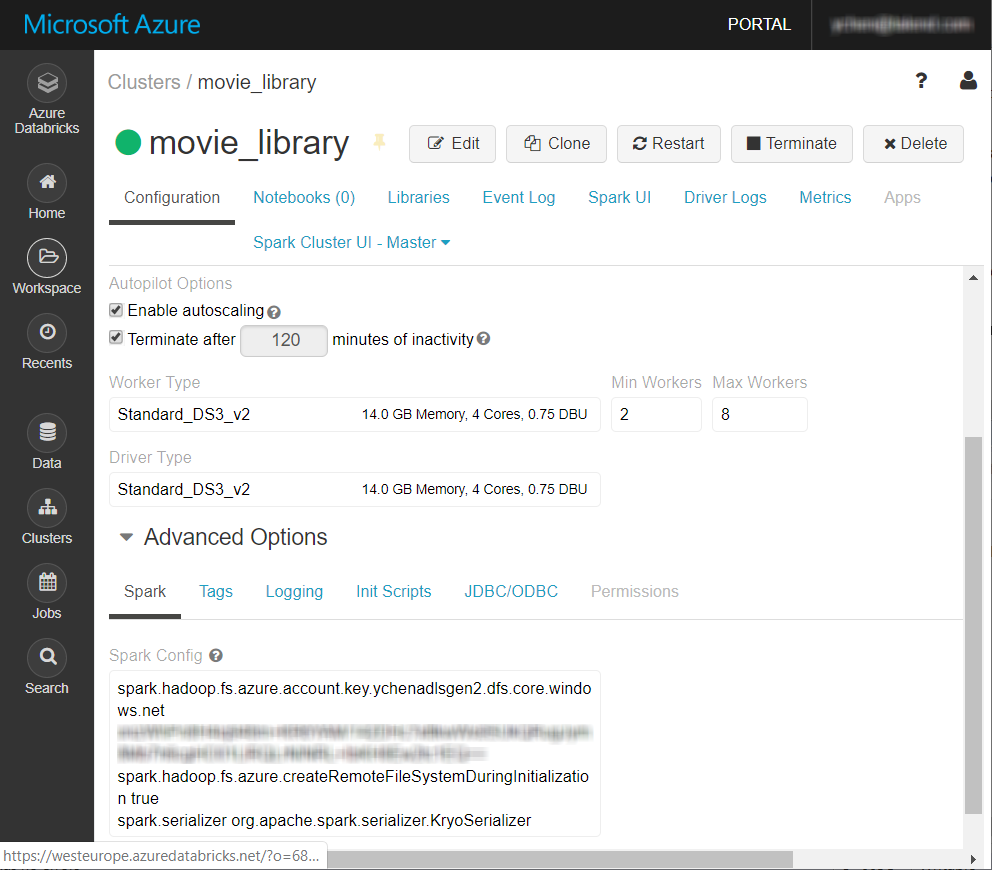
-
Select the Enter manually Hadoop
services check box to manually enter the configuration
information for the Databricks connection being created.

Results
The new connection, called movie_library in this example, is displayed under the Hadoop cluster folder in the Repository tree view.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!