
Loading/unloading data to/from Amazon S3
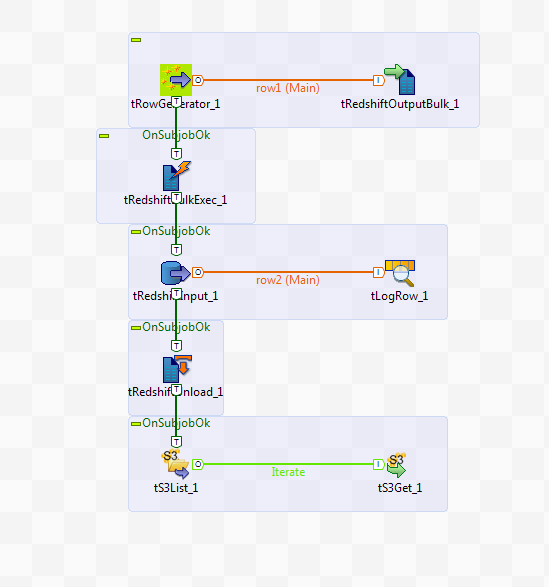
This scenario describes a Job that generates a delimited file and uploads the file to S3, loads data from the file on S3 to Redshift and displays the data on the console, then unloads the data from Redshift to files on S3 per slice of the Redshift cluster, and finally lists and gets the unloaded files on S3.
For more technologies supported by Talend, see Talend components.
Prerequisites:
The following context variables have been created and saved in the Repository tree view. For more information about context variables, see Talend Studio User Guide.
-
redshift_host: the connection endpoint URL of the Redshift cluster.
-
redshift_port: the listening port number of the database server.
-
redshift_database: the name of the database.
-
redshift_username: the username for the database authentication.
-
redshift_password: the password for the database authentication.
-
redshift_schema: the name of the schema.
-
s3_accesskey: the access key for accessing Amazon S3.
-
s3_secretkey: the secret key for accessing Amazon S3.
-
s3_bucket: the name of the Amazon S3 bucket.
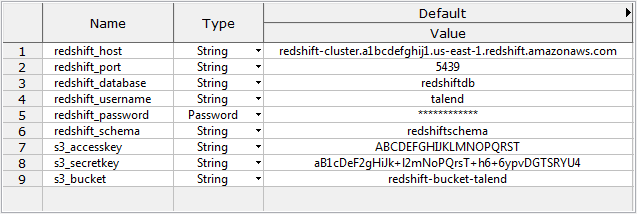
Note that all context values in the above screenshot are for demonstration purposes only.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!