
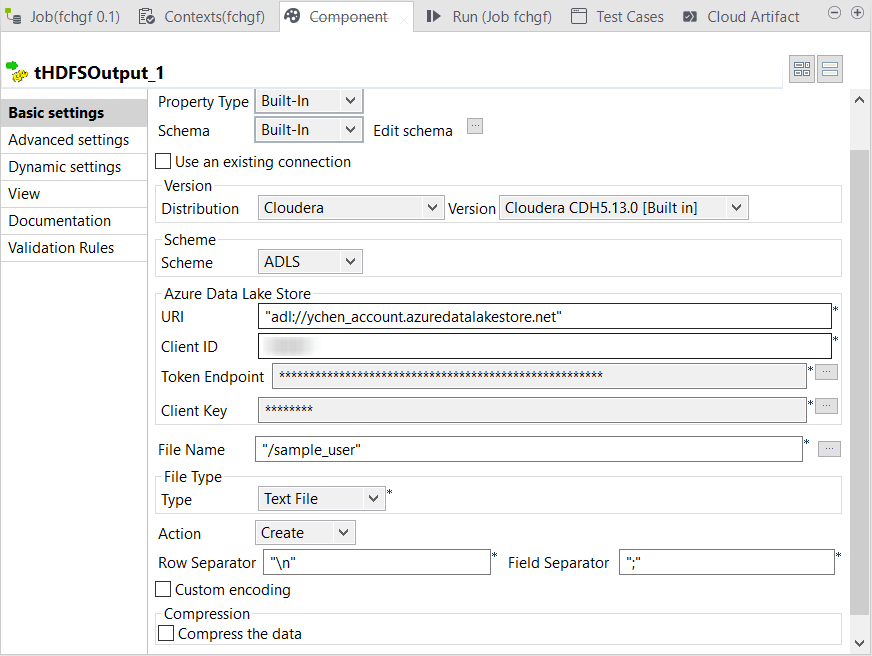
Configuring the HDFS components to work with Azure Data Lake Storage
Procedure
-
Double-click tHDFSOutput to open its
Component view.
Example
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!