For further information about the related rights and permissions,
see the documentation or contact the administrator of the Hadoop cluster to be
used.
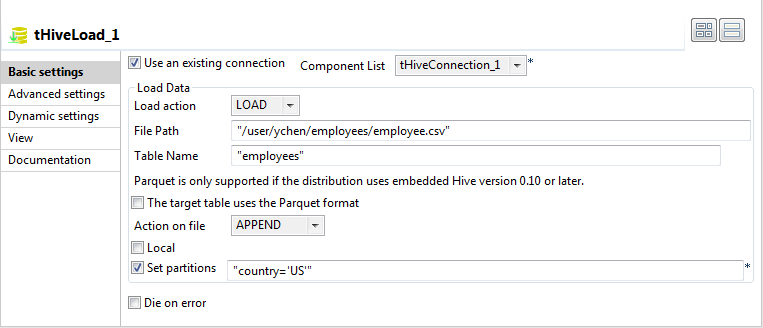
Note if you need to read data from a local file system other than the HDFS
system, ensure that the data to be read is stored in the local file system
of the machine in which the Job is run and then select the Local check box in this Basic settings view. For example, when the connection mode
to Hive is Standalone, the Job is run in
the machine where the Hive application is installed and thus the data should
be stored in that machine.