
Accessing the selected data
Procedure
-
Double-click tCacheOut to open its
Component view.
 This component stores the selected data into the cache.
This component stores the selected data into the cache. -
On the output side of the schema editor, click the
 button to export the schema to the local file system and
click OK to close the editor.
button to export the schema to the local file system and
click OK to close the editor.
-
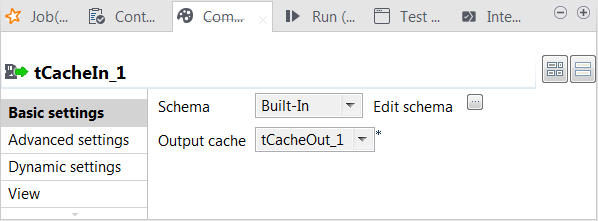
Double-click tCacheIn to open its
Component view.
-
Click the [...] button next to Edit
schema to open the schema editor and click the
 button to import the schema you exported in the previous
step. Then click OK to close the editor.
button to import the schema you exported in the previous
step. Then click OK to close the editor.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!