
Configuring the components
Procedure
-
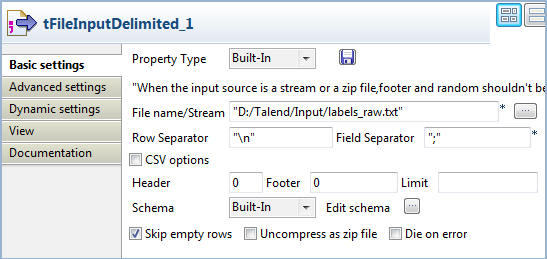
Double-click the tFileInputDelimited
component to open its Basic settings
view.
-
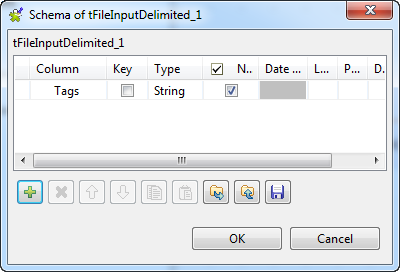
Add one column named Labels.
-
Enter "," as Field Separator.

-
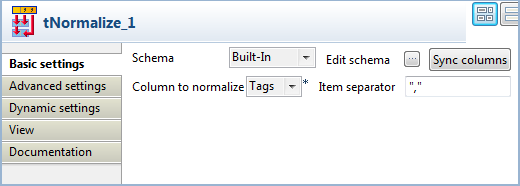
Define the column the normalization operation is based on.
In this example, the input schema has only one column, Labels.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!