
Using two parsing levels to extract information from unstructured data
This scenario applies only to Talend Data Management Platform, Talend Big Data Platform, Talend Real-Time Big Data Platform, Talend MDM Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
For more technologies supported by Talend, see Talend components.
This scenario describes how to build a set of rules to extract some information from unstructured data. It explains how to use a basic ANTLR rule to tokenize data then how to use an advanced rule to check each token created by ANTLR against a regular expression.
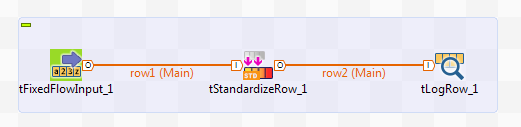
This scenario uses:
-
a tFixedFlowInput component to create the unstructured data strings.
-
a tStandardizeRow component to define the rules necessary to extract the liquid amounts from the data strings.
-
a tLogRow component to display the output data.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!