
Converting Jobs
You are able to create a Job by converting it from a different framework, such as from Standard to Spark.
This option is recommended if the components used in a source Job are also available to the target Job. For example, if you need to convert a Standard Job to a Spark Batch Job.
Procedure
-
If you need to modify the descriptive information of the Job, make the changes in
the corresponding fields.
If you need to change the information in the uneditable fields, you have to use the Project settings wizard to make the desired changes. For further information, see Customizing project settings.
Example
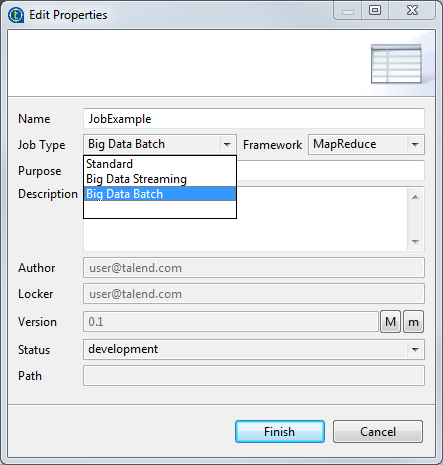
Results
Then the converted Job appears under the Big Data Batch node.
Note that you can also select the Duplicate option from the contextual menu to access the conversion; this approach allows you to keep the source Job with its original framework but create the duplicate one on the target framework.
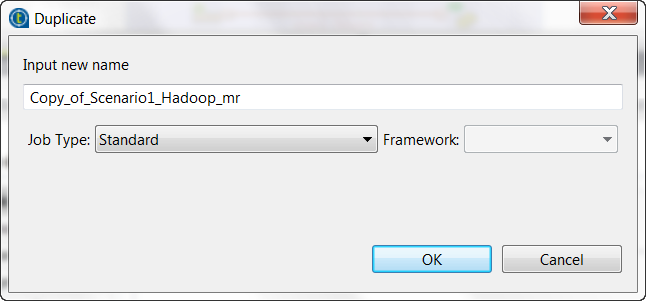
You can as well repeat this procedure from a MapReduce Job to convert it to a Standard Job or to other frameworks. For this purpose, the option to select from the contextual menu is Edit Big Data Batch properties.
If you are using in the Standard Job a connection to Hadoop that has been defined in the Repository, then once you click the Finish button, the Select node wizard is displayed to allow you to select this connection and thus to automatically reuse this connection in the MapReduce Job to be created.
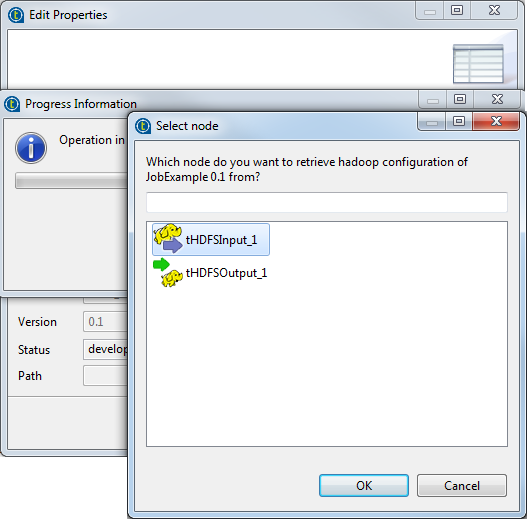
Each component appears in this wizard is being used by the source standard Job. By selecting it, you are reusing the Hadoop connection metadata it contains for the MapReduce Job you are creating.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!