
Creating a connection to an HDFS file
Before you begin
- You have selected the Profiling perspective.
- You have created a connection to the Hadoop distribution.
Procedure
Results
The new HDFS connection is listed under the Hadoop connection in the DQ Repository tree view.
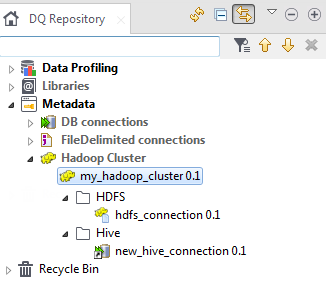
For more information about creating HDFS connections, see Centralizing HDFS metadata.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!