
Defining a blocking key
About this task
Defining a blocking key is not mandatory but strongly advisable. Using a blocking key to partition data in blocks reduces the number of records that need to be examined as comparisons are restricted to record pairs within each block. Using blocking column(s) is very useful when you are processing a big dataset.
Procedure
-
Click the name of the column(s) you want to use to partition the processed data in
blocks.
Blocking keys that have the exact name of the selected columns are listed in the Blocking Key table.
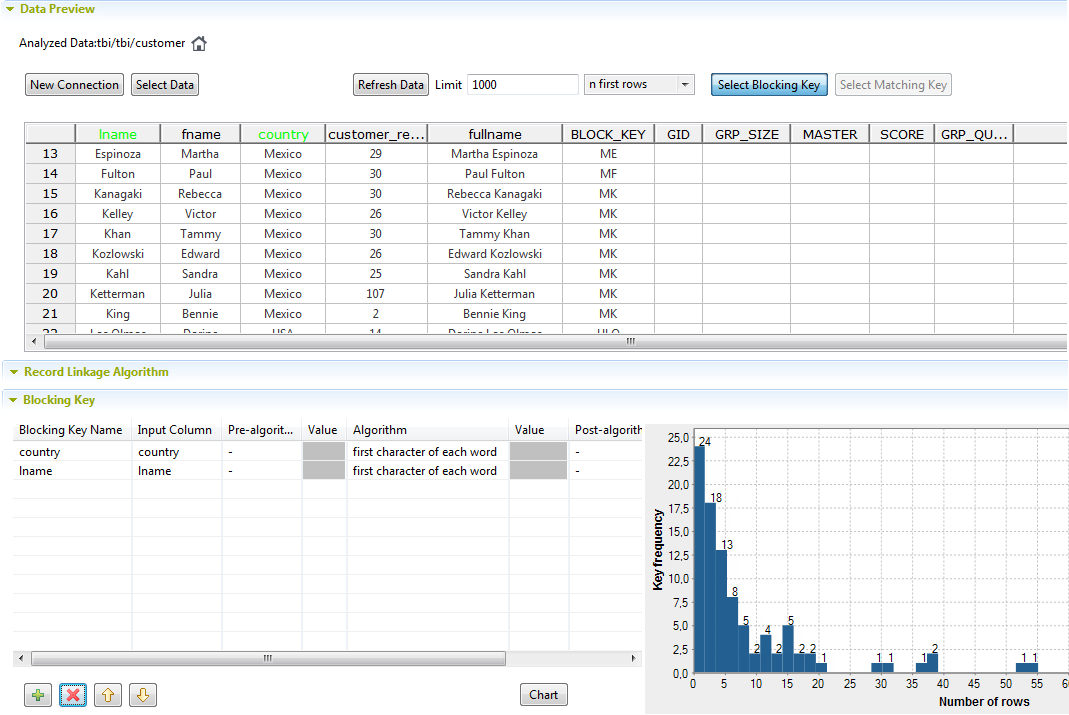 You can define more than one column in the table, but only one blocking key will be generated and listed in the BLOCK_KEY column in the Data table.For example, if you use an algorithm on the country and lnamecolumns to process records that have the same first character, data records that have the same first letter in the country and last names are grouped together in the same block. Comparison is restricted to record within each block.To remove a column from the Blocking key table, right-click it and select Delete or click on its name in the Data table.
You can define more than one column in the table, but only one blocking key will be generated and listed in the BLOCK_KEY column in the Data table.For example, if you use an algorithm on the country and lnamecolumns to process records that have the same first character, data records that have the same first letter in the country and last names are grouped together in the same block. Comparison is restricted to record within each block.To remove a column from the Blocking key table, right-click it and select Delete or click on its name in the Data table.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!