
Using Explicit Join
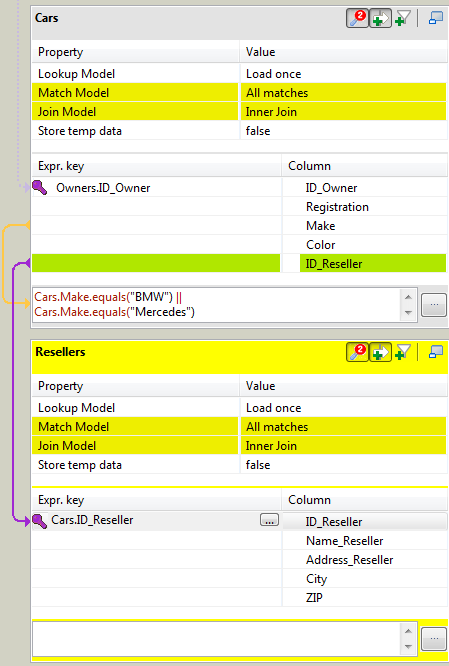
In fact, Joins let you select data from a table depending upon the data from another table. In the Map Editor context, the data of a Main table and of a Lookup table can be bound together on expression keys. In this case, the order of table does fully make sense.
Simply drop column names from one table to a subordinate one, to create a Join relationship between the two tables. This way, you can retrieve and process data from multiple inputs.
The join displays graphically as a purple link and creates automatically a key that will be used as a hash key to speed up the match search.
You can create direct joins between the main table and lookup tables. But you can also create indirect joins from the main table to a lookup table, via another lookup table. This requires a direct join between one of the Lookup table to the Main one.
The Expression key field which is filled in with the dragged and dropped data is editable in the input schema, whereas the column name can only be changed from the Schema editor panel.
You can either insert the dragged data into a new entry or replace the existing entries or else concatenate all selected data into one cell.
For further information about possible types of drag and drops, see Mapping the Output setting.
Creating a Join automatically assigns a hash key onto the joined field name. The key symbol displays in violet on the input table itself and is removed when the Join between the two tables is removed.
Related topics:
Along with the explicit Join you can select whether you want to filter down to a unique match or if you allow several matches to be taken into account. In this last case, you can choose to consider only the first or the last match or all of them.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!