
Buffering data
This scenario describes an intentionally basic Job that bufferizes data in a child Job while a parent Job simply displays the bufferized data onto the standard output console.
For more technologies supported by Talend, see Talend components.
-
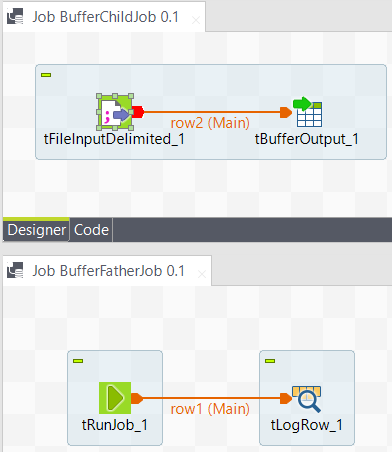
Create two Jobs: a first Job (BufferFatherJob) runs the second Job and displays its content onto the Run console. The second Job (BufferChildJob) stores the defined data into a buffer memory.
-
On the first Job, drop the following components: tRunJob and tLogRow from the Palette to the design workspace.
-
On the second Job, drop the following components: tFileInputDelimited and tBufferOutput the same way.
Let's set the parameters of the second Job first:
-
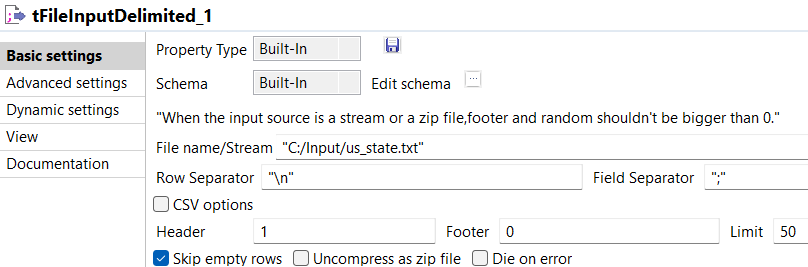
Select the tFileInputDelimited and on the Basic Settings tab of the Component view, set the access parameters to the input file.
-
In File Name, browse to the delimited file whose data are to be bufferized.
-
Define the Row and Field separators, as well as the Header.
-
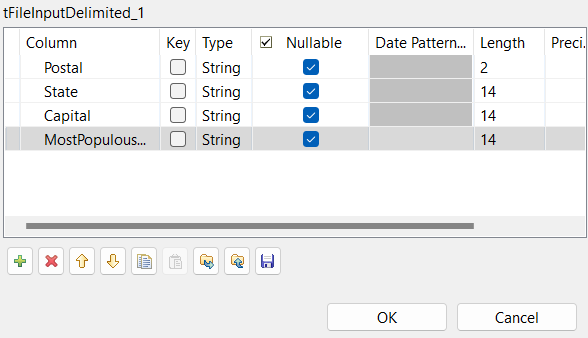
Describe the Schema of the data to be passed on to the tBufferOutput component.
-
Select the tBufferOutput component and set the parameters on the Basic Settings tab of the Component view.
-
Generally the schema is propagated from the input component and automatically fed into the tBufferOutput schema. But you could also set part of the schema to be bufferized if you want to.
-
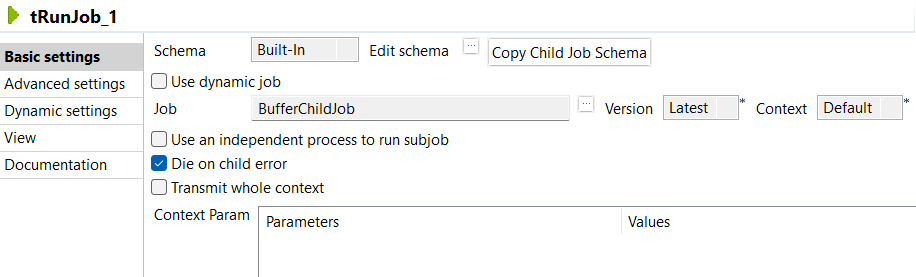
Now on the other Job (BufferFatherJob) Design, define the parameters of the tRunJob component.
-
Edit the Schema if relevant and select the column to be displayed. The schema can be identical to the bufferized schema or different.
-
You could also define context parameters to be used for this particular execution. To keep it simple, the default context with no particular setting is used for this use case.
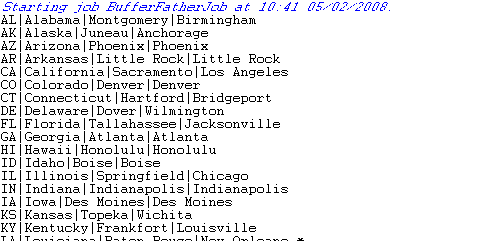
Press F6 to execute the parent Job. The tRunJob looks after executing the child Job and returns the data onto the standard console:
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!