
Batch processing large lookup tables
This article explains how to use batch processing to handle large lookup tables.
One way to approach this issue is to use a process called Batching. Batching allows a batch of the records to be processed in a single run, which is done iteratively to create more batches and process all the records.
Each iteration will process and extract a fixed number of records from the source and the lookup tables, perform a join and load the target table.
This way you can control the number of records (batchrec variable) that the process holds in the memory.
To do this you can use Context variables and the tLoop, tContextLoad, tMap, and tJava components.
Procedure
-
Use context variables to make the Job dynamic. Different values
can be used for context variables in different environments such as DEV and PROD. This also makes the Job flexible and it does not need any
code changes across environments.
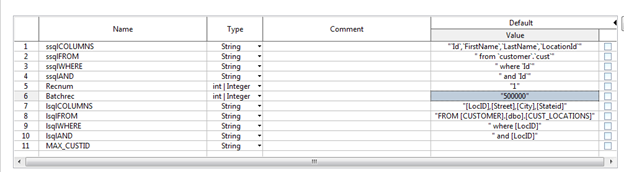
Context variables used in this Job Variable Description Recnum This variable is used as a starting point of the run. It is set to "1" by default for this Job. Batchrec This variable is used as the number of the records that you want the Job to process in each iteration. By making this variable dynamic, you can control how many records you want to process for each batch. MAX_CUSTID This variable is used to stop the process after the last iteration, which is after reading the last record. This variable is loaded using the tContextLoad component. The SQL run is as follows: "SELECT 'MAX_CUSTID' as Key, max(id) as Value FROM `customer`.`cust` "
-
Use the sssql and lsql variables to build the SQL that the
tMysqlInput and tMSSqlInput executes on the database. The
columns chosen in ssqlCOLUMNS and
lsqlCOLUMNS should be the same as the
schema defined in the input components.
For example, the query in the customer (tMysqlInput) component is defined as below, making the full query dynamic.
" SELECT " + context.ssqlCOLUMNS + context.ssqlFROM + context.ssqlWHERE + ">=" + context.Recnum + context.ssqlAND + "<" + (context.Recnum + context.Batchrec) ;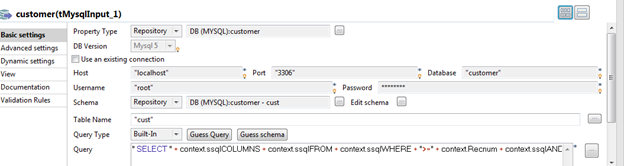
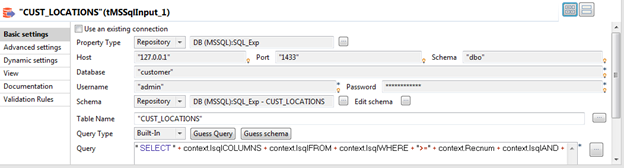
A similar SQL query is defined on the CUST_LOCATIONS (tMSSqlInput) component.
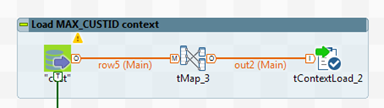
-
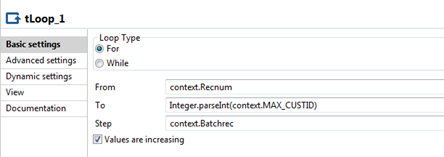
Configure the tLoop
component as follows.
The context variables defined above are used in the tLoop component as shown below. So for each iteration until the maximum customer id, the batch record number defined in the Batchrec variable is used to retrieve the records from the source and lookup tables.
-
Configure the tJava
component as follows.
This component is used to increment the starting cust_id by the number of the records being processed by each batch.

-
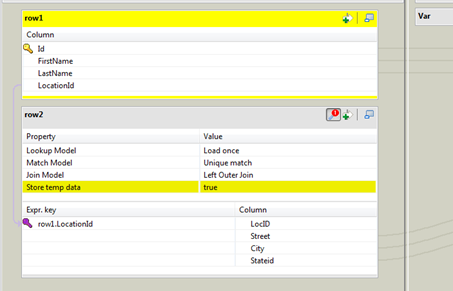
Configure the tMap
component as follows.
This component is used for the join condition. The Lookup Model is set as Load Once as your lookup table is static. Match Model is set as Unique match as you do not expect the lookup table to have duplicates. Join Model is set as Left Outer Join as you want source data to be loaded into the target even if a location is not found.
-
Connect the subJobs using OnSubJobOk and OnComponentOk triggers.
Do not connect tLoop directly to the tMysqlInput component. And do not connect tJava (Update record counter) directly to tMysqlOutput_1. The tLoop and tJava need to be part of their own subJobs.
The complete Job looks as shown in the screenshot below.
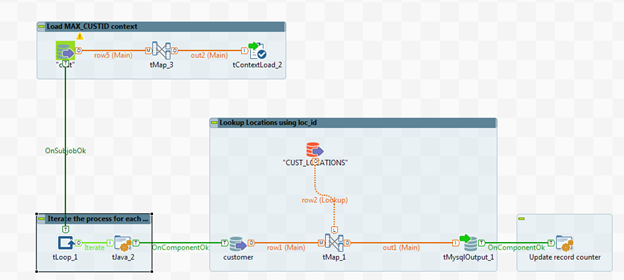
Results
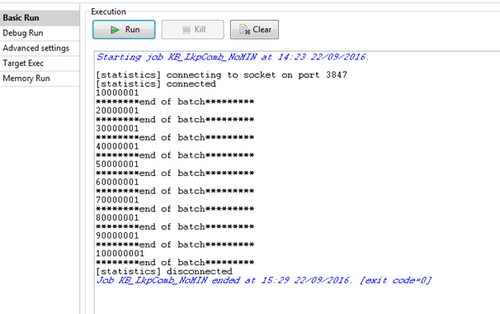
Here is the log from a sample run where the source table (cust) has 100 million rows and the lookup table (CUST_LOCATIONS) has 70 million rows. Batchrec="10000000".
The Job took 66 minutes to run and ran within the memory available on the execution server. It did not get impacted with out of memory exceptions.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!