
Doing a fuzzy match on two columns and outputting the match, possible match and non match values
This scenario applies only to Talend Data Management Platform, Talend Big Data Platform, Talend Real-Time Big Data Platform, Talend MDM Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
This scenario describes a six-component Job that aims at:
-
Matching each processed group number in the grp column against the entries that have exactly the same values in the reference input file.
-
Checking the edit distance between the entries in the firstname column of an input file against those of the reference input file.
The outputs of these two matching types are written in three output files: the first for match values, the second for possible match values and the third for the values for which there are no matches in the lookup file.
In this scenario, you have already stored the main and reference input schemas in the Repository. For more information about storing schema metadata in the Repository, see Managing metadata in Talend Studio.
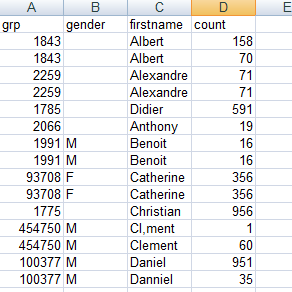
The main input file contains four columns: grp, gender, firstname and count. The data in this input file have problems such as duplication, first names spelled differently or wrongly, different information for the same customer.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!