
Merging the content of several rows using different columns as rank values
This scenario applies only to Talend Data Management Platform, Talend Big Data Platform, Talend Real-Time Big Data Platform, Talend MDM Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
This scenario describes a three-component Job that uses the tSurviveFields component to merge, based on different rank values, the content of data rows in different columns and then writes the result in an output file.
In this scenario, we have already stored the input schemas of the input file in the Repository. For further information about storing schema metadata in the Repository, see Managing metadata in Talend Studio.
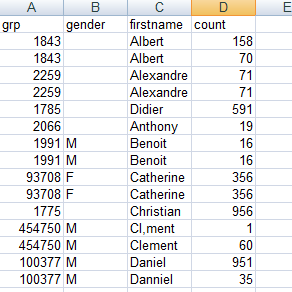
The input file contains four columns: grp, gender, firstname and count. The data in the input file has problems such as duplication, first names spelled differently or wrongly and different information for the same customer.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!