
Reading the sample data from S3
Procedure
-
Double-click tFileInputParquet to open its
Component view.
Example
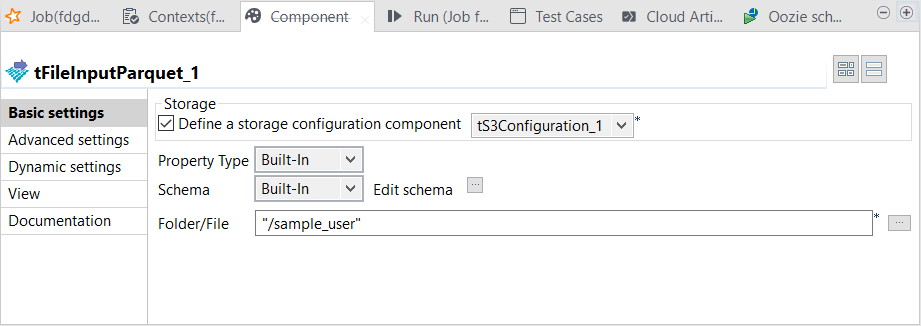
-
Click the [+] button to add the schema columns for
output as shown in this image.
Example

Results
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!