
Writing and reading data from S3 (Databricks on AWS)
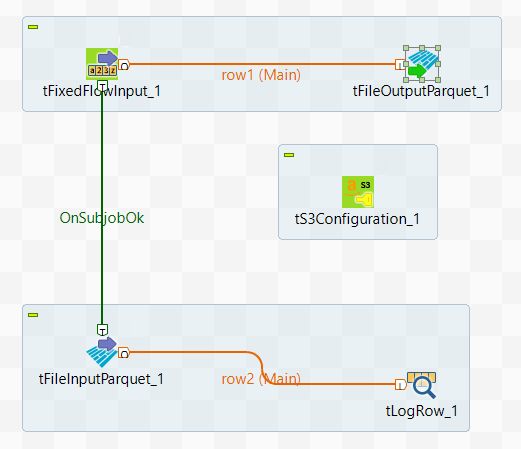
In this scenario, you create a Spark Batch Job using tS3Configuration and the Parquet components to write data on S3 and then read the data from S3.
This scenario applies only to subscription-based Talend products with Big Data.
For more technologies supported by Talend, see Talend components.
The sample data reads as
follows:
01;ychenThis data contains a user name and the ID number distributed to this user.
Note that the sample data is created for demonstration purposes only.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!