
Use the Hadoop property filter of Talend Studio to resolve the Hive-on-Tez issue for Spark Jobs on Hortonworks
Procedure
-
Select the Hortonworks version you are using and then perform one of the following operations:
-
If your Hortonworks has Ambari installed, select the Retrieve configuration from Ambari or Cloudera radio button and click Next. Then do the following:
-
In the wizard that is opened, enter the Ambari credentials in the corresponding fields and click Connect.
Then a cluster name is displayed on the Discovered clusters drop-down list.
-
On the list, select your cluster and click Fetch to retrieve the configuration of the related services.

-
Click the [...] button next to Hadoop property filter to open the wizard.
-
-
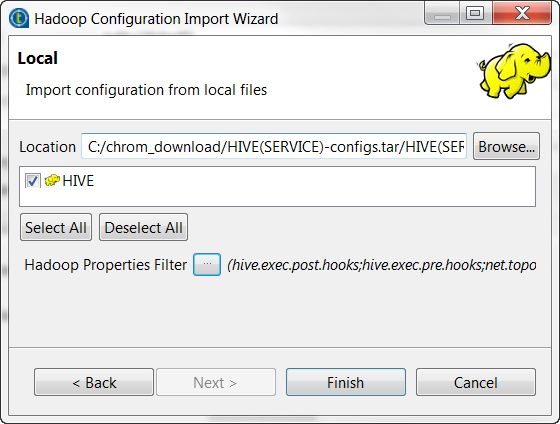
If your Hortonworks does not have Ambari, you have to import the Hive configuration files from a local directory. This means you need to contact the administrator of your cluster to obtain the Hive configuration files or download these files yourself.
Once you have these files, do the following:
-
In Hadoop configuration import wizard, select the Import configuration from local files radio button and click Next.
-
Click Browse... to find the Hive configuration files.
-
Click the [...] button next to Hadoop property filter to open the wizard.
-
-
-
Click the [+] button to add one row and enter hive.execution.engine in this new row to filter this property out.

Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!