
How to: Talend for "Data Vaults"
This article tutorial details the Job design patterns and best practice recommendations for building data population and extraction procedures for a Data Vault using Talend.
Enterprise Data Warehouses have evolved. Big data ecosystems have emerged as a predominant storage destination and the 'Data Lake' has become the preferred terminology for raw business data processing. Directly impacted from this significant paradigm shift are data modeling methodologies. STAR schemas, while robust and popular in their day, have become insufficient in this Brave New Data World. Fact and Dimension tables can be forced into a Hadoop environment, however they simply fall short in various ways; on the update requirements in particular. STAR schemas also generally require highly cleansed data and do not adapt well when upstream systems change. These factors make utilization of Big Data STAR schemas problematic at its best and destined for disappointments.
Data Vaults to the rescue! Dan Linstedt, author and inventor of Data Vault 1.0 and 2.0 understood that 3NF and STAR schemas simply fail to deliver on the promise of Enterprise Data Warehouses ( What is "The Data Vault" and Why Do We Need It? ). Data Modeling is the 1st essential step in the process of creating and managing Enterprise Data Warehouses and Data Lakes on Big Data ecosystems. Moving data into and getting data out of these infrastructures is the next essential step. This is where Talend comes in.
Please read the blog links in the paragraph above for some important background first. Then proceed for details on how to build Talend Jobs for Data Vaults.
| All of the Jobs in this DV Tutorial have been designed using best practices in canvas layout, documentation, error handling and flow control (please read the Talend Blogs on Job Design Patterns Part 1 , Part 2 , Part 3 , & Part 4 for more information). |
As a start to this tutorial the data model involved is presented below. This particular tutorial is focused on a common data workflow using relational data models only. As indicated in the blogs above, Big Data data models are also quite possible. Look for subsequent versions on this tutorial that demonstrates these variants. To fully understand this tutorial the three (3) data models here show a SOURCE database, a DATA VAULT database, and a DATA MART database.
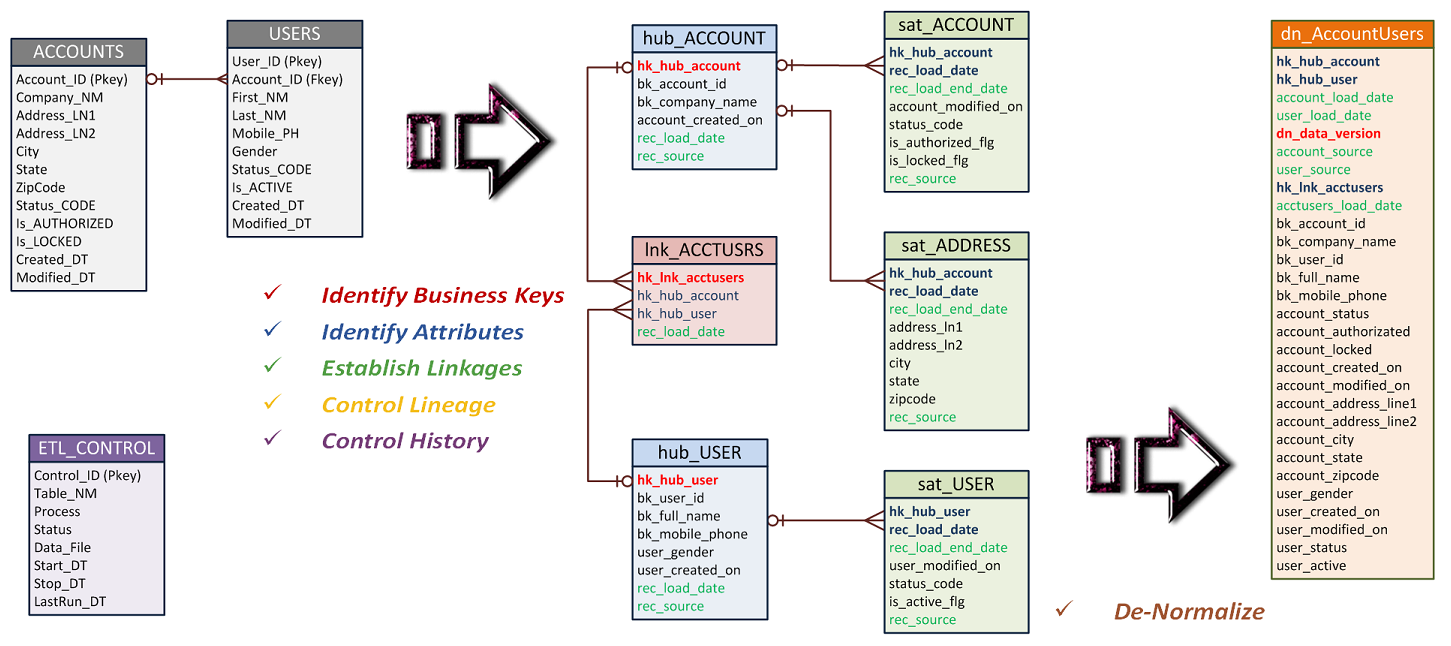
The SOURCE data model is represented by the ACCOUNTS and USERS tables where an account record can have zero to many user records and a user record must have one and only one account parent record. This is defined physically as a Foreign Key on the Account_ID column in the USERS table to the ACCOUNTS table.
The DATA VAULT data model is represented by the hub_ACCOUNT , hub_USER , lnk_ACCTUSRS , sat_ACCOUNT , sat_ADDRESS , and sat_USER tables. The HUB tables contain the identified business keys and the SAT tables contain the attributes that change over time, all derived from the SOURCE database. T he lnk_ACCTUSRS table provides the zero to many relationship of the hub_ACCOUNT and hub_USER tables as defined in the foreign key between the ACCOUNTS and USERS tables in the SOURCE data model . Physical Foreign Keys are defined for the LNK and SAT tables to the HUB tables as shown in the data model.Data Vault Model using Point-In-Time (PIT Tables)
A revised DATA VAULT data model incorporating PIT and BRIDGE tables can help achieve an interesting option: A 100% INSERT ONLY Data Warehouse!

Added are the pit_ACCOUNTS , pit_USERS , and the brdg_ACCTUSERS tables . The PIT tables contain the Hash Keys from each of the related HUB and SAT tables plus a Snapshot Date. As rows are inserted into the HUB and SAT tables, a record is also added to the PIT table. Notice that the 'rec_load_end_date' is no longer included in the SAT tables. This design eliminates the need to UPDATE the SAT tables, thus providing a 100% INSERT ONLY option. The PIT Tables are designed to setup an EQUA-JOIN on a HUB and it's related SAT tables. When a Snapshot is desired where two or more HUB tables are involved, use a BRIDGE table in a similar way.
Note that the PIT and BRIDGE tables have a tendency to grow rapidly so an archival mechanism may be warranted when large volumes of data are involved.
The DATA MART or De-Normalized data model is represented by the dn_AccountUsers table. This table contains the versioned, historical records extracted from the DATA VAULT data model to provide consistent analytics and reporting capabilities for current values and for values 'back-in-time'.
While this tutorial is not about how to design a DATA VAULT data model, from the ERD shown above, the basic ideas are shown; here is a summary of the 5 simplified steps:
| Identify Business Keys | Relational source tables generally include fields that represent static values providing meaningful, non-mutable, business identifiers; these are your Business Keys used in HUB tables; HUB tables should only include columns that contain values that never change. |
| Identify Attributes | The remaining attributes from source tables that represent values which do change over time are placed into SAT tables; SAT tables should be appropriately organized and contain the remaining columns that contain values that can change. Sometimes these source columns are better suited for LNK tables; for example transaction details on a ORDER>LINE ITEM structure. |
| Establish Linkages | HUB tables have unique surrogate keys, usually hash-keys set as primary keys, and never use any surrogate keys from their source as the primary key (those become business keys). SAT tables have surrogate keys that are composed of the parent HUB table primary key and the rec_load_date only. This establishes a foreign key relationship to the HUB table. Notice that a unique index on the HUB hash key and rec_load_date is created to allow for the foreign key from the SAT table. LNK tables create a linkage between HUB tables. LNK tables have unique surrogate keys, also best defined as a hash key set as a primary key. LNK tables then contain the corresponding hash keys from 2 or more HUB tables being linked together. |
| Control Lineage | Tracking when and where data originates is essential to a Data Vault data model. A rec_load_date provides the date as to when the record arrived into the Data Vault, NOT the date the record was created in the source table. The rec_source then provides location and/or name of the source table as it is possible for a single Data Vault table to contain records from multiple source tables. Generally HUB tables must contain these two columns. The rec_source column may be unnecessary in LNK and SAT tables however the Data Vault specification includes it. |
| Control History | As SAT tables accumulate historical versions of a particular record the rec_load_date and the rec_load_end_date provide a mechanism to allow storage of these records over time. The rec_load_end_date is null for the most current version of a record and contains the value of the next rec_load_date record when it arrives into the table. This requires an update operation on the previous record to set the rec_load_end_date and enables queries against the SAT tables using these two dates to pull the current values and values 'back in time'. Note that for a Big Data Data Vault these are differences here as update operations are highly undesirable or possibly not available. |
The use case for this tutorial is to setup and populate the SOURCE database with interesting data , extract this data into CSV files and then bulk loading into the DATA VAULT database, transforming the data to match the HUB/SAT/LNK tables. Once processed into the DATA VAULT database the tutorial extracts the data, transforming and loading a denormalized (or flattened) representation of the data into the DATA MART database. ETL_CONTROL tables are utilized in the SOURCE and DATA VAULT databases to to support the data processing of the delta (or latest) records from the SOURCE through to the DATA MART, then the DATA MART databases.

The Data Integration ETL process summarized above shows how this Talend for "Data Vaults" tutorial is implemented. While focused on a relational centric data flow, several combinations of SOURCE > DATA VAULT > DATA MART data flow processing options are possible. The following overview presents several worth consideration. Future tutorials will provide details on some of these, so watch for them.

Note that a DATA MART which contains de-normalized tables (as in this tutorial), column-based databases or column-store NoSQL solutions are highly recommended. This provides best results when running aggregation queries for analytics. A relational database can be used as we are doing in this tutorial for simplicity and ease of understanding the principles involved.
Set Up ProcessA full project archive file that contains all the Jobs and referenced objects required to set up, inspect, and execute are included with this tutorial. The prerequisites include:
- Laptop/Desktop w/Windows 7 or better (MacOs can be used instead)
- 64 bit
- 8 Gb RAM minimum
- 500 Mb disk recommended
- MySQL v6.2+ server instance
- download
- local or network accessible
- 64-bit
- MySQL Workbench (optional)
-
Talend Data Integration and compatible JDK
- Due to the ' Joblet' feature utilized in this tutorial a subscription license is required to run these Jobs
- download Talend Studio
Follow these instructions to complete the setup for the tutorial.
Step 1:- Install JDK
- ensure JAVA_HOME is set correctly
- Install Talend Studio
-
Install MySQL server (and optionally MySQL Workbench)
- Create two (2) MySQL databases: sourcedv and relationaldv
- Create a 3rd MySQL database for the PIT version: relationaldvpit
- Create a MySQL user/password: Talend/admin and grant full access to the databases created
- Start Talend Studio
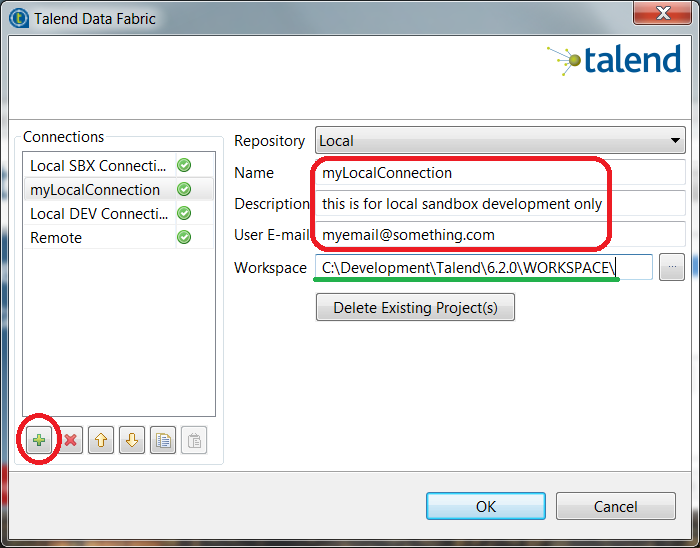
- Create a Local Connection for your workspace
- a specific directory location other than the specified default is highly recommended
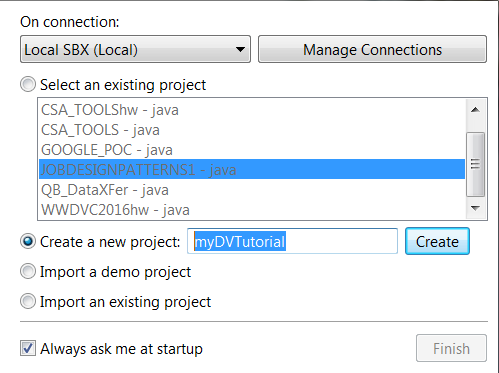
- Create a Local Project called myDVTutorial
- Open the myDVTutorial project
- Create a Local Connection for your workspace
- Once Talend Studio is
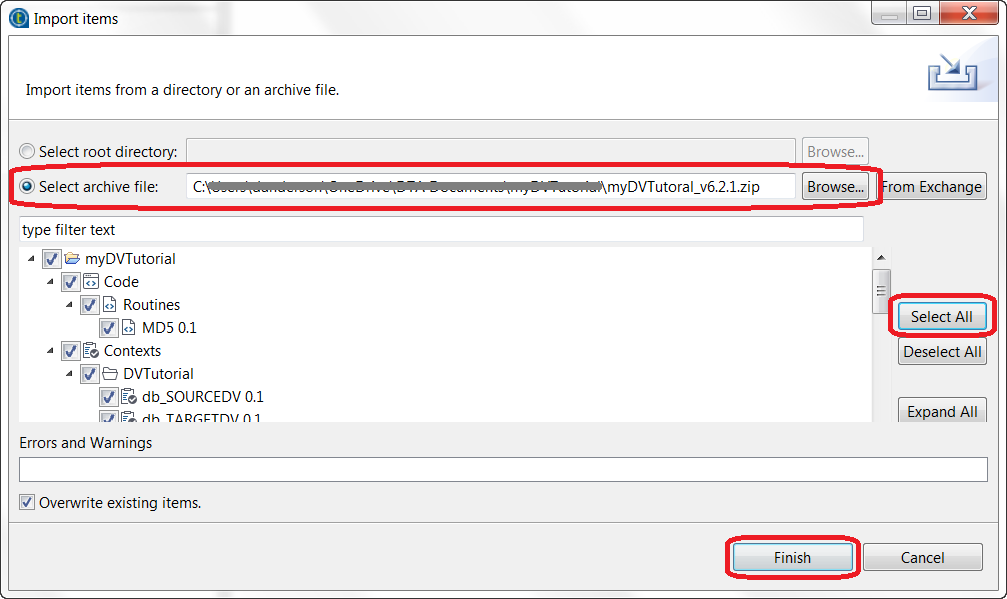
open, right click on the Job Designs folder in the Repository to import items
- Download the myDVTutorial_v6.2.1.zip sample from the Downloads tab on the left panel of this page
- Locate the archive file you downloaded
- Select All and click Finish
You are now ready to continue.
Talend Job FlowSeveral Talend Jobs are included in the myDVTutorial project you just loaded. These Jobs represent each step in the overall process to populate, process data end-to-end demonstrating the loading of a Data Vault and it's downstream Data Mart from scratch and and then re-processing the Jobs fornew and updated records from the source. Here is the basic flow we will follow:

PIT Table Orchestration
The process flow required for the DATA VAULT having PIT and BRIDGE tables is identical, simply run the identified alternate Jobs below.
Initialize SOURCE/TARGET Database Process
Find the Job called setup_SOURCEdv in the DVTutorial folder under the repository Job Designs. This Job:
- Connects to the MySQL database as 'localhost' (you'll need to change this if connecting to a MySQL database on a remote server) with auto_commit ON
- Upon successful connection the ACCOUNTS, USERS, and ETL_CONTROL tables are dropped if they exist and recreated
- The Foreign Key from the USERS table to the ACCOUNTS table is created
- The ELT_CONTROL table primary key is set to auto increment
- The ACCOUNTS and USERS tables are populated with generated data and the MAX(Created_DT) is saved in a global variable
- The ETL_CONTROL table is seeded with the required process control records which includes the saved creation date
- Once completed, the database connection is closed and the Job exits
Notice that the tParallelize component has been used to drop tables and that the ACCOUNTS table is dropped only after the USERS table has been dropped. This is due to the foreign key constraint. Instead of a tParallelize component, the Job design could have used OnSubJobOK triggers instead.
setup_SOURCEdv JOB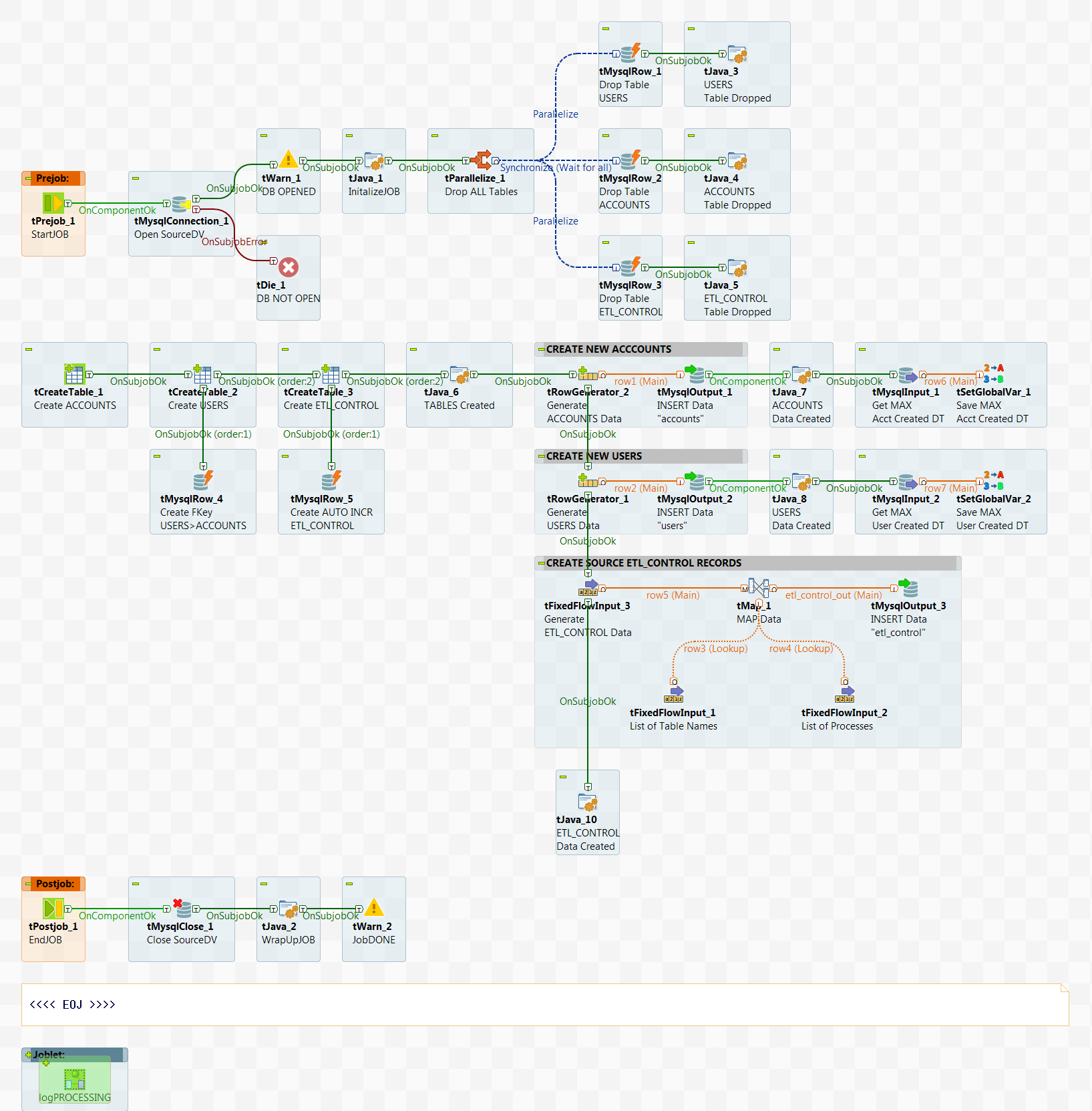
Run this Job! If any errors have occurred in execution the most likely problem is that the MySQL database connection has failed. Correct the problem and re-run the Job until it will execute correctly to completion. Logs are created in the c:/Temp/dvLOGS directory for more information on Job execution. Using the MySQL Workbench (if installed) open the database and verify that the tables have been correctly created and populated with interesting data. You may of course use the MySQL command prompt instead.
You can run this Job repeatedly to reset your environment.
Next find the Job called setup_TARGETdv in the myDVTutorial folder under the repository Job Designs. This Job:
- Connects to the MySQL database as 'localhost' (you'll need to change this if connecting to a MySQL database on a remote server) with auto_commit ON
- Upon connection the DATA VAULT tables and views are dropped if they exist and
recreated, including:
- HUB_ACCOUNT, HUB_USER, SAT_ACCOUNT, SAT_ADDRESS, SAT_USER, and LNK_ACCTUSRS
- dvv_HUB_ACCOUNT, dvv_HUB_USER, dvv_SAT_ACCOUNT, dvv_SAT_ADDRESS, and dvv_SAT_USER
- DN_ACCOUNTUSERS
- ELT_CONTROL
- A unique index for the HUB_ACCOUNT and HUB_USER tables are created
- Foreign keys from the SAT_ACCOUNT, SAT_ADDRESS, and SAT_USERS tables to their corresponding HUB tables are created
- The ELT_CONTROL table primary key is set to auto increment and is seeded with the required process control records
- Once completed, the database connection is closed and the Job exits
Notice that the first tParallelize component has been used to drop tables and that the HUB tables are dropped after the SAT and LNK tables have been dropped. This is due to the foreign key constraints from the SAT and LNK tables to the HUB tables. The second tParallelize component creates all the base tables and finally creates the required views. Take a look at the CREATE VIEW syntax which limits the returned result set based upon a join with the ETL_CONTROL table. More on that later.
Notice also that the DN_ACCOUNTUSERS table which is technically a DATA MART table, has been included in the relationaldv (DATA VAULT) database. This was done for simplification and would normally be placed in it own database.
setup_TARGETdv JOB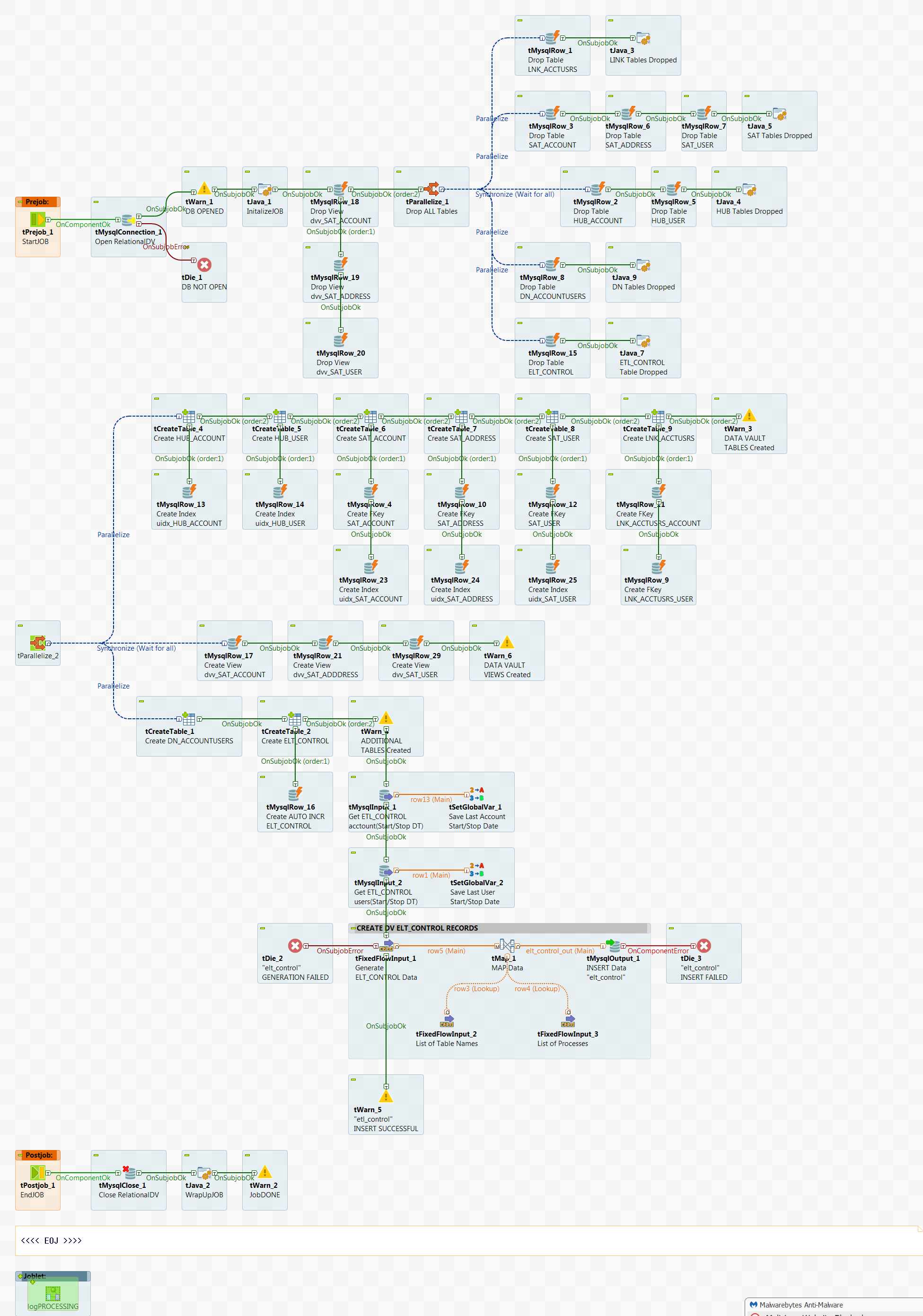
Setup TARGETdv for PIT Tables
As the TARGETdv contains the modified SAT tables plus the PIT and BRIDGE tables, a different setup Job is used. Instead of the setup_TARGETdv Job use the setup_TARGETdvPIT Job. Notice the additional table drop/create components and the changes for views.
setup_TARGETdvPIT JOB
| DO NOT RUN THIS JOB YET! |
Once you have run the dump_SOURCEdv Job as described next you can run this Job! If any errors have occurred in execution the most likely problem is that the MySQL database connection has failed. Correct the problem and re-run the Job until it will execute correctly to completion. Logs are created in the c:/Temp/dvLOGS directory for more information on Job execution. Using the MySQL Workbench (if installed) open the database and verify that the tables have been correctly created. There should be no data in these tables at this point. You may of course use the MySQL command prompt instead.
You can run this Job repeatedly to reset your environment.
Both Jobs share a common Joblet called logPROCESSING which catches unexpected errors and logs them. Output from Job execution can be found in the c:/Temp/dvLOGS directory and opened in Microsoft Excel for viewing. This Joblet can be enhanced in several ways; Feel free to incorporate this into your projects and modify to suit your needs.
logPROCESSING JOBLET
Additionally, shared Joblets for ETL_CONTROL table processing called sdvETLCONTROL and rdvELTCONTROL which inserts or updates records used to determine a current data flow status. These control records provide the mechanism to run the Jobs in this tutorial, end-to-end, regardless of when or how often you run them. With this capability only data that has not yet been processed will be included in any end-to-end run.ELT_CONTROLpit JOBLET
As the Target DV database for using PIT and BRIDGE tables is a different schema and connection so we've used a new version of the rdvELTCONTROLpit Joblet to insert and update data flow control records.
Notice that on the tMysqlOutput component the field options in the advanced settings tab of the component is very specific to how columns can be utilized.
Remember that the ETL_CONTROL tables use the auto increment feature on the primary key. That key is used for updates and should not be used on any insert. On the basic settings tab the action on data is set to ' Insert or Update '. While currently this tutorial does not use the Joblet to INSERT, it is designed to do so. This would become quite useful in more complex data processing scenario.
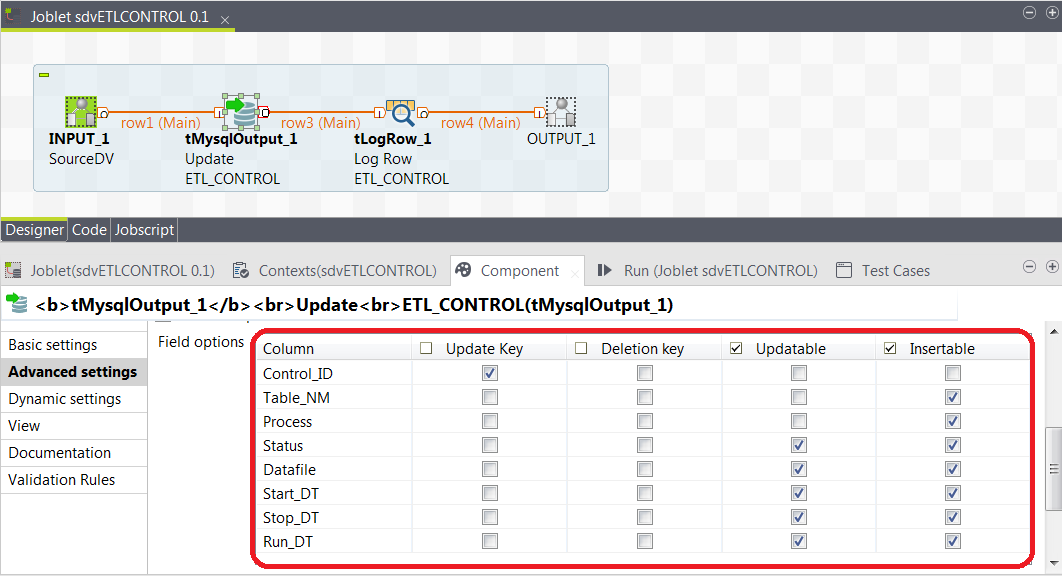
Notice that a second rdvELTCONTROL Joblet exists which not only changes from ETL to ELT , but is placed in the DATA VAULT database for process control between the HUB/SAT/LNK tables and the De-Normalized Table. The schema is identical however the data contained is not. Inspect the setup Jobs for specific details. As we demonstrate both ELT and ETL processing below, we will use the same ELT_CONTROL table for both. Notice also that this ELT_CONTROL table does not require the Datafile column.
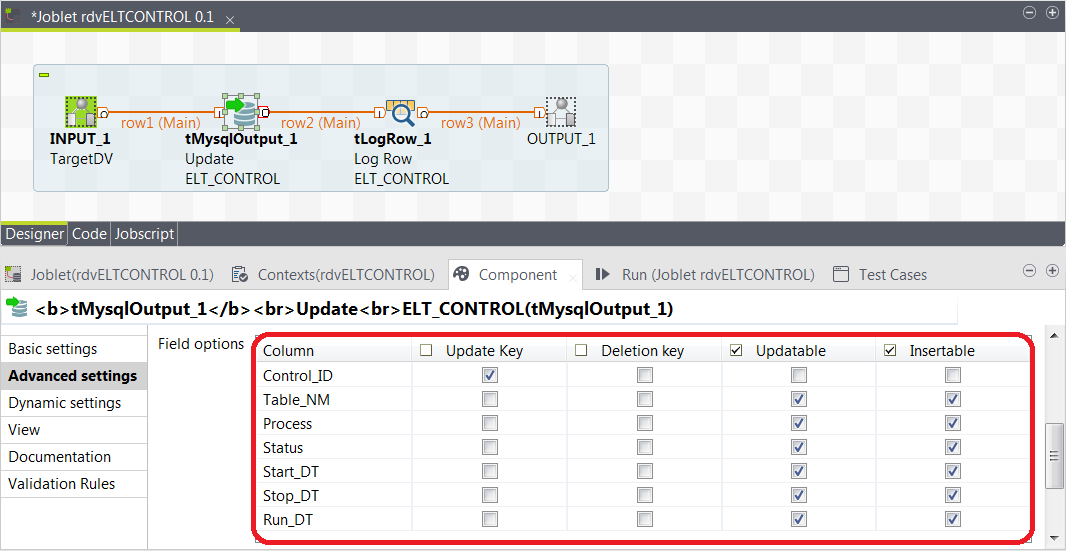
Dump/Load TARGET (Data Vault) Process
The Dump/Load process is designed in two steps. The DUMP extracts data from SOURCE tables where their Created_DT and/or Modified_DT values are greater than the last Stop_DT in the ETL_CONTROL table, then writing the data into a bulk load formatted (tab delimited) flat file. This enables the process to dump only new or changed records since the last time the Job was run. The LOAD inserts the flat file data into the TARGET (DATA VAULT) tables. A fairly simple and straight forward process.
Find the Job called dump_SOURCEdv in the myDVTutorial folder under the repository Job Designs. This Job:
- Connects to the MySQL database as 'localhost' (you'll need to change this if connecting to a MySQL database on a remote server) with auto_commit OFF
- Sets the Client database Time zone (default is GMT -08:00); the Initialize Job component contains some context variables to assist your customization requirements
- The first tMysqlInput component reads the ETL_CONTROL table in the sourcedv
database for process control
- All records set as Process=' DUMP ' and Status=' INITIALIZED ' are retrieved
- The tMap component splits the control records by table: ACCOUNTS and USERS
- The tSetGlobalVar components saves the Start_DT and Stop_DT specific to each source table for subsequent processing
- The tJavaRow components overrides the ETL_CONTROL record for setting the intermediate status of ' IN PROCESS ' and the data file name
- The sdvETLCONTROL Joblet is called to update the ETL_CONTROL table
- The tBufferOutput components saves the specific ETL_CONTROL record for subsequent update upon Job exit
- The next tMysqlInput components extracts data from the source tables
controlled by the Created_DT and Modified_DT columns
- This allows the extract to determine all newly created records and all changed records since the last dump
- The tMysqlOutputBulk components write out the data to corresponding CSV files located in the c:/Temp/dvFiles directory
- Once completed, the database connection is closed, the ETL_CONTROL records are updated with an intermediate status of ' DUMPED ', and the Job exits
Notice the usage of OnSubJobOK versus OnComponentOK which controls the data flow from operational components. Observe that in the 'DUMP ACCOUNT RECORDS' and 'DUMP USER RECORDS' sub Jobs, while we connect to it using an OnComponentOK (which is the only option for a tBufferOutput component) we use an OnSubJobOK on the tMysqlOutput component. This ensures that the code contained in the tJava component is not executed until ALL records have been read from the 'accounts' table and written to the dump file.
dumpSOURCEdv JOB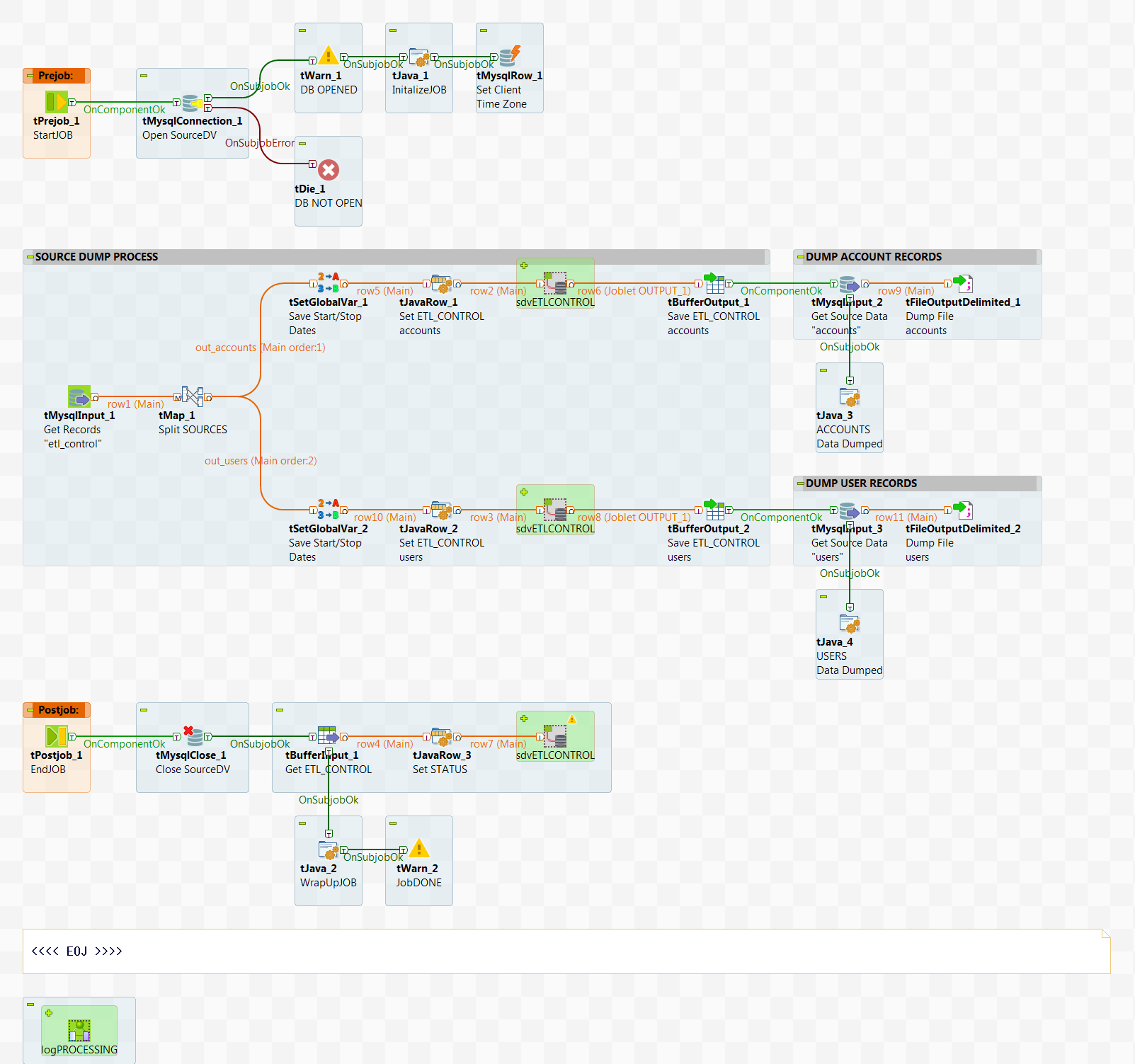
Run this Job! If any errors have occurred in execution the most likely problem is that the MySQL database connection has failed. Correct the problem and reset the process from the top, re-running the setup Jobs then the dump Job, until it will execute correctly to completion. Logs are created in the c:/Temp/dvLOGS directory for more information on Job execution. Bulk output files can be found in the c:/Temp/dvFILES directory.
| NOW YOU CAN RUN THE setup_TARGETdv (or setup_TARGETdvpit) Job! |
Next find the Job called load_TARGETdv in the myDVTutorial folder under the repository Job Designs. This Job:
-
Connects twice to the MySQL database as 'localhost' (you'll need to change this if connecting to a MySQL database on a remote server)
- One to the RELATIONALdv (as the TARGET) with auto_commit ON
- One to the SOURCEdv (as the SOURCE) with auto_commit OFF (for ETL_CONTROL processing)
- Both connections are then set to local time zones (as a best practice)
-
The first tMysqlInput component reads the ETL_CONTROL table in the sourcedv database for process control
-
All records set as Process=' DUMP ' and Status=' DUMPED ' are retrieved
-
- The first tMap component splits the control records by table: ACCOUNTS and USERS
- The tSetGlobalVar components save the DataFile and Run_DT specific to each source table for subsequent processing
- The tJavaRow components overrides the ETL_CONTROL record for setting the intermediate status of ' IN PROCESS ' and the run date
- The sdvETLCONTROL Joblet is called to update the ETL_CONTROL table
- The tBufferOutput components saves the specific ETL_CONTROL record for subsequent update upon Job exit
- The tFileInputDelimited components read the specified data files
- Notice that the schema in use maintains the original SOURCE table structure through this data flow
- The next tMap components check to see if the Modified_DT is null on the
output flow
- when the expression is true this represents new accounts or users can be inserted into the Data Vault
- when the expression is false then this represents existing accounts or
users that need:
- 1st to update the existing SAT tables rec_load_end_date
-
and then inserted as new records
-
Once completed, the database connection is closed, the ETL_CONTROL records are updated with a completed status of ' LOADED ', and the Job exits
loadTARGETdv JOB
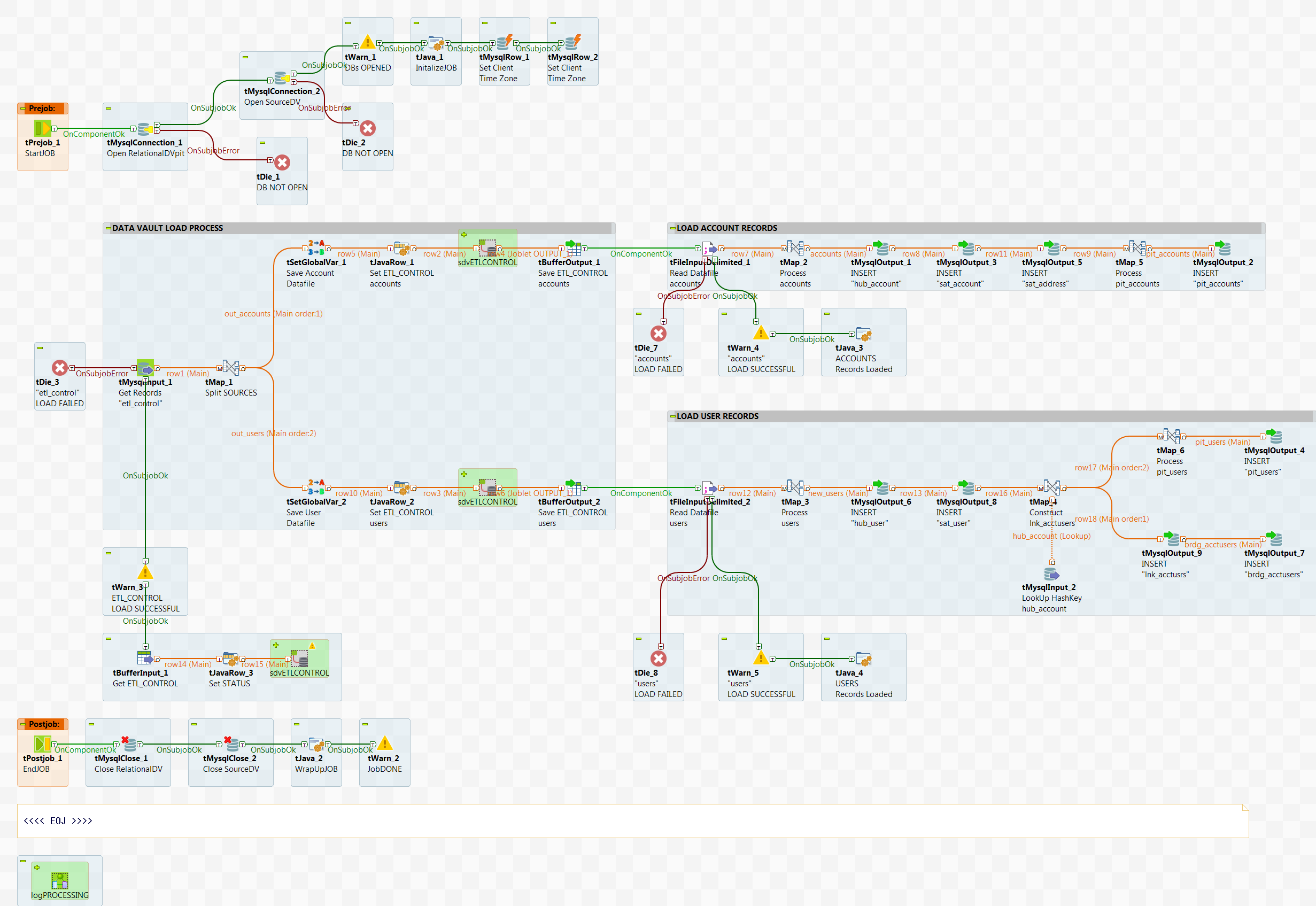
Run this Job! If any errors have occurred in execution the most likely problem is that the MySQL database connection has failed. Correct the problem and reset the process from the top, re-running the setup Jobs then the dump Job, until it will execute correctly to completion. Logs are created in the c:/Temp/LOGS directory for more information on Job execution. Using the MySQL Workbench (if installed) open the RELATIONALdv database and verify that the Data Vault tables have been correctly created. You may of course use the MySQL command prompt instead. All the HUB, SAT, and LNK tables should now contain the data loaded from the data files.
Load TARGETdv PIT version
The load_TARGETdvPIT Job is somewhat different as it no longer needs to update the 'rec_load_end_date' in the SAT tables. Instead it needs to load the PIT and BRIDGE tables. Otherwise the flow is essentially the same.
loadTARGETdvPIT JOB
This Job runs just like its non-PIT counterpart except when it gets to the tMap component upon reading the data file. No longer splitting out New versus Existing records, it passes all records through, inserting them to the HUB table (ignoring Duplicates) then on to inserting into the SAT tables. Once these records are stored an additional tMap component sorts out the necessary Hash Keys and rec_load_dates for the PIT and/or BRIDGE tables.
De-Normalization DATA MART Table Process
Once the SOURCE data has been processed (dump/load) into the Data Vault, is the Data Warehouse complete? It does have the raw data and due to the Data Vault data modeling methodology historical information is available. So, yes in part the Data Warehouse is 'Ready' for use. Many reports, lists, and extracts can be pulled from this 'Data Lake'. There is however one additional step that makes the effort to get here so much more interesting. Analytics! It is possible to create SQL aggregation queries directly against the Data Vault. It is also possible to process the data one more time into a format that is better suited for these types of queries. When placed in a column-based database or column-store NoSQL data store, de-normalized to reflect both current and historical information, analytic reporting gets much easier. Pulling data out of the Data Vault also suggests that business users who may understand how to write SQL queries would be highly efficient if they could do so against a simplified representation of the data.
As data changes upstream and gets processed into the Data Vault, a 'synchronization' process satisfies this additional requirement. Find the sync_ELT_DATAMART Job in the myDVTutorial folder under the repository Job Designs. This Job:
-
Connects twice to the MySQL database as 'localhost' (you'll need to change this if connecting to a MySQL database on a remote server)
- Both connections are to the RELATIONALdv database (as the TARGET)
-
The 1st connection is for READ operations with auto_commit OFF , the 2nd is for WRITE operations with auto_commit ON
- Both connections are then set to local time zones (as a best practice)
- the tMysqlInput component reads the ELT_CONTROL table in the relationaldv
database for process control
- All records set as Process=' SYNC ' and Status=' INITIALIZED ' are retrieved
- The tJavaRow components overrides the ELT_CONTROL record for setting the intermediate status of ' IN PROCESS ' and the data file name
- The rdvELTCONTROL Joblet is called to update the ELT_CONTROL table
- The tBufferOutput components saves the specific ELT_CONTROL record for subsequent update upon Job exit
- The first 3 tELTMysqlInput components extracts data from the HUB tables using
the LNK table for joins
- This supports the foreign key relationship from the SOURCE database where 0-to-many Users may exist and any Account
- The last 3 tELTMysqlInput components extract data from the SAT views which
join internally on the ELT_CONTROL table
- This supports the requirement to retrieve only those ' new ' or ' changed ' records since the last synchronization
- The tELTMysqlMap component constructs the SQL query required for processing
- The tELTMysqlOutput component inserts the result set into the dn_AccountUsers table
-
Once completed, the database connection is closed, the ELT_CONTROL records are updated with a completed status of ' SYNC ED ', and the Job exits
sync_ELT_DATAMART JOB
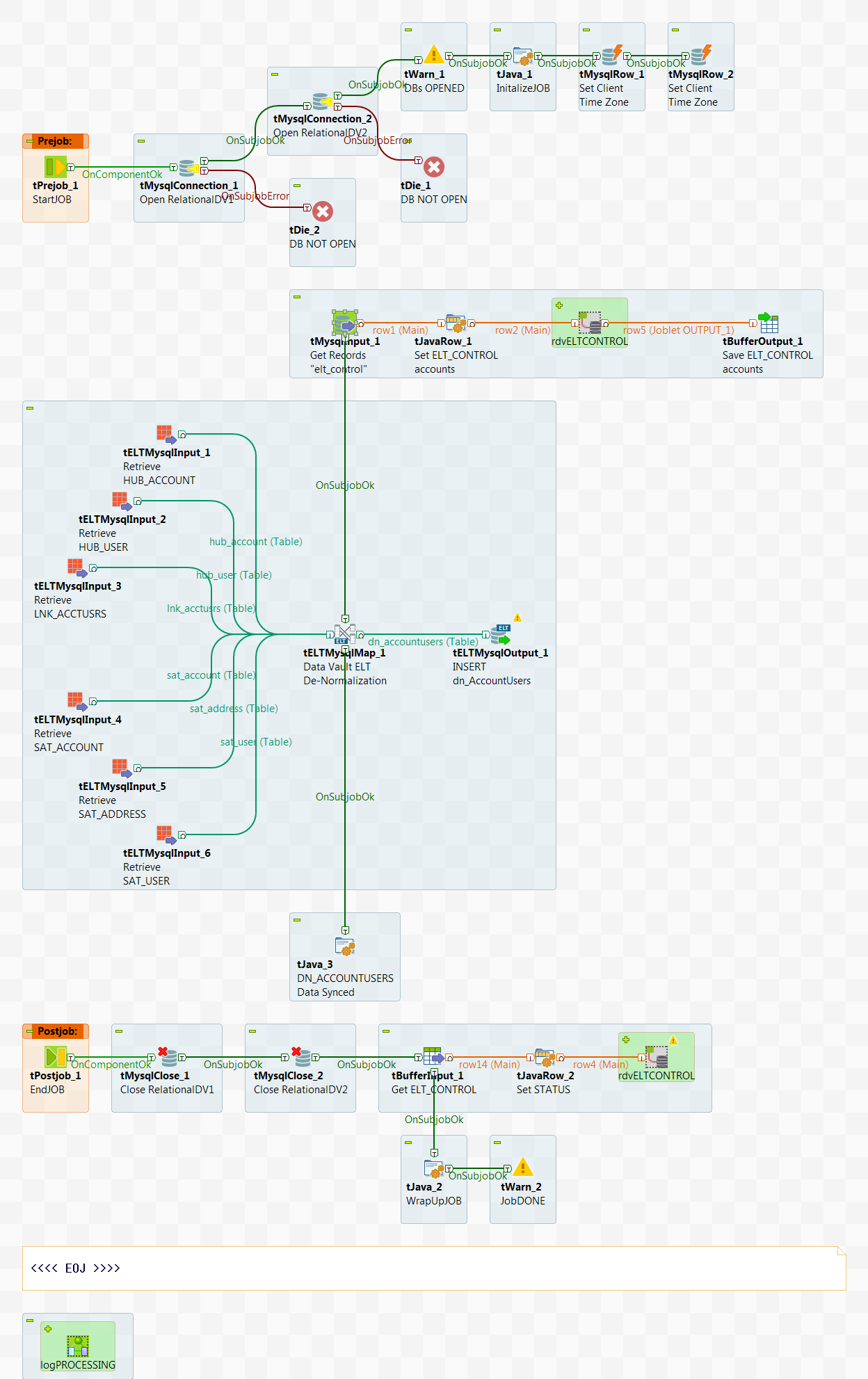
Notice in the tELTMysqlMap component that we are using an 'Implicit Join' which constructs the ELT SQL query as a list of table/view FROM objects and using the WHERE clause to establish the join criteria. We actually do NOT want to do an OUTER JOIN here as we expect to have a complete and full representation of the data being synced. More complex requirements may require that you do this slightly differently.
The most important part of this mapping is the dn_data_version column. Notice the ' Case ' statement (which you will need to open the source code to read fully). This is the critical requirement that returns the next data version number for each record in this process. Without this the de-normalized table is useless. With this feature, queries against this table were MAX(dn_data_version) is incorporated the most current records are returned. When the query however needs to go 'Back In Time', then all the rec_load_dates are these to accommodate historical references.
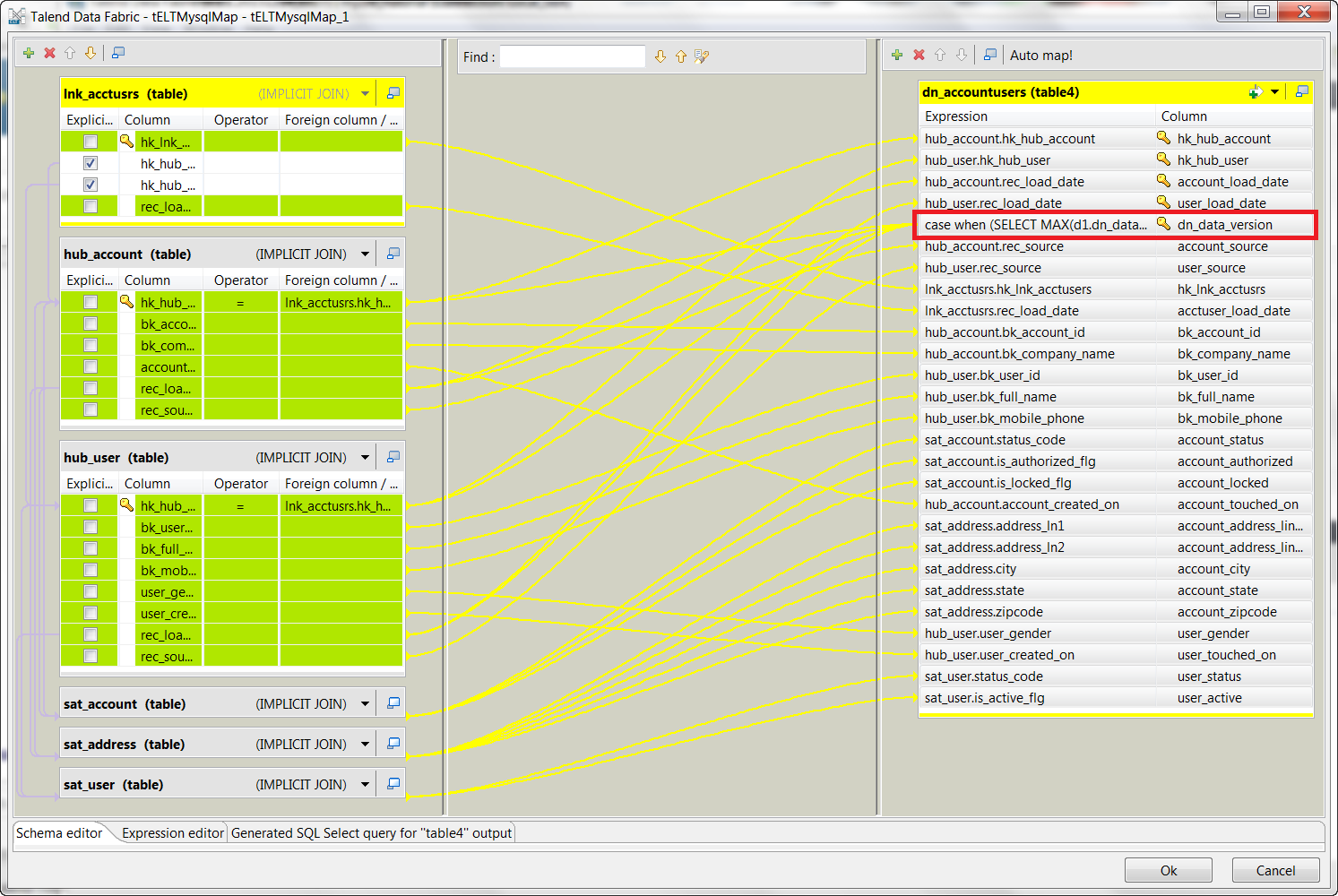
Run this Job! If any errors have occurred in execution the most likely problem is that the MySQL database connection has failed. Correct the problem and reset the process from the top, re-running the setup Jobs, the dump and load Jobs, finally this Job until it will execute correctly to completion. Logs are created in the c:/Temp/dvLOGS directory for more information on Job execution. Using the MySQL Workbench (if installed) open the RELATIONALdv database and verify that the Data Vault tables have been correctly created. You may of course use the MySQL command prompt instead. The ' dn_AccountUsers ' table should now contain the data synchronized from the Data Vault.
To satisfy the curious, an ETL version of the de-normalization process is also included here. While not as elegant as the ELT version, just as effective when using a relational data model. Find the sync_ETL_DATAMART Job in the myDVTutorial folder under the repository Job Designs. This Job:
-
Connects twice to the MySQL database as 'localhost' (you'll need to change this if connecting to a MySQL database on a remote server)
- Both connections are to the RELATIONALdv database (as the TARGET)
-
The 1st connection is for READ operations with auto_commit OFF , the 2nd is for WRITE operations with auto_commit ON
- Both connections are then set to local time zones (as a best practice)
- the tMysqlInput component reads the ELT_CONTROL table in the relationaldv
database for process control
- All records set as Process=' SYNC ' and Status=' INITIALIZED ' are retrieved
- The tJavaRow components overrides the ELT_CONTROL record for setting the intermediate status of ' IN PROCESS ' and the data file name
- The rdvELTCONTROL Joblet is called to update the ELT_CONTROL table
- The tBufferOutput components saves the specific ELT_CONTROL record for subsequent update upon Job exit
- The subsequent tMysqlInput components, processing upon the LNK_ACCTUSRS
table, constructs all records from DATA VAULT as it passes them downstream in the flow
- We process on the LNK_ACCTUSRS table as it provides a complete stream of all existing DATA VAULT Account/User records
- We lookup the HUB_ACCOUNT and HUB_USER records to capture the business keys and static values (like Created_DT)
- We Merge the SAT_ACCOUNT, SAT_ADDRESS, and SAT_USER records from the Views which limit the result set to 'new' and/or 'updated' rows only
- Finally we filter out all the records that are NOT new and NOT updated, resulting in the records of interest in the current execution
- The tMap component conducts a final, and critical step, calculating the appropriate 'dn_data_version' value for the records being processed
-
The tMysqlOutput component writes out (INSERTS) the result set to the de-normalized ' dn_AccountUsers ' table
sync_ETL_DATAMART JOB

Alternatively to the sync_ELT_DATAMART , run this Job! If any errors have occurred in execution the most likely problem is that the MySQL database connection has failed. Correct the problem and reset the process from the top, re-running the setup Jobs, the dump and load Jobs, finally this Job until it will execute correctly to completion. Logs are created in the c:/Temp/LOGS directory for more information on Job execution. Using the MySQL Workbench (if installed) open the RELATIONALdv database and verify that the Data Vault tables have been correctly created. You may of course use the MySQL command prompt instead. The ' dn_AccountUsers ' table should now contain the data synchronized from the Data Vault.
Touch the Data Process & Re-run End-to-EndNow that we have generated and pushed data through from the SOURCE database through the DATA VAULT into a DATA MART, things get interesting. The remaining question in this process is how do we process the end-to-end data flow again . Creating new records and changing others. The data flow needs to support processing the delta since the last run. This is where the CONTROL tables come into play and specialized handling affect the data flow. We've hinted at this above so it should becoming clear. To solidify the process let's create some new data, and update some existing data and re-run the process. Skipping the setup Jobs, the following Jobs ' touch ' the SOURCE database and inserts the appropriate CONTROL records in both the SOURCE and TARGET databases.
Find the touch_SOURCEdv Job in the myDVTutorial folder under the repository Job Designs. This Job:
- Connects to the MySQL database as 'localhost' (you'll need to change this if connecting to a MySQL database on a remote server) with auto_commit O
- The first set of tMysqlInput components retrieve the MAX value for Account_ID
and User_ID and the ETL_CONTROL Last Stop Dates
- The Lasty Stop Date is the date the previous SOURCE Dump Process took place
- This is a critical value to setup as the Start Date for the next SOURCE Dump Process
- The tSetGlobalVar components saves these values for subsequent processing
- The UPDATE ACCOUNT RECORDS and UPDATE USER RECORDS Sub Jobs:
- Retrieves some existing ACCOUNT and USER records based upon an interesting criteria (inspect the SQL to find out what)
- Modifies some values for the selected ACCOUNT and USER records
- Executes the UPDATE on these selected rows
- The CREATE NEW ACCOUNTS and CREATE NEW USERS Sub Jobs:
- Generate some additional ACCOUNT and USER records
- Saves the generated rows
- The CREATE SOURCE ETL CONTROL RECORDS Sub Job:
- Sets up a fresh set of control records ready to run the DUMP SOURCE process
-
Once completed, the database connection is closed and the Job exits

Run this Job! The SOURCE ACCOUNT and USER tables should now have a number of new and updated records. Run a SELECT COUNT(*) on these tables to see how many rows now exist. You may also run a query for records that now have a Modified_DT value for the modified rows.
| RUN THE dump_SOURCE Job! |
This will create fresh dump files that contain only the new and updated rows.
Find the Job called touch_TARGETdv in the DVTutorial folder under the repository Job Designs. This Job:
- Connects to the MySQL database as 'localhost' (you'll need to change this if connecting to a MySQL database on a remote server) with auto_commit ON
- The tMysqlInput component retrieves the ELT_CONTROL Last Stop Date
- The tSetGlobalVar components saves the value for subsequent processing
- The CREATE DV ELT CONTROL RECORDS Sub Job:
- Sets up a fresh set of control records ready to run the LOAD TARGET process
- Once completed, the database connection is closed and the Job exits
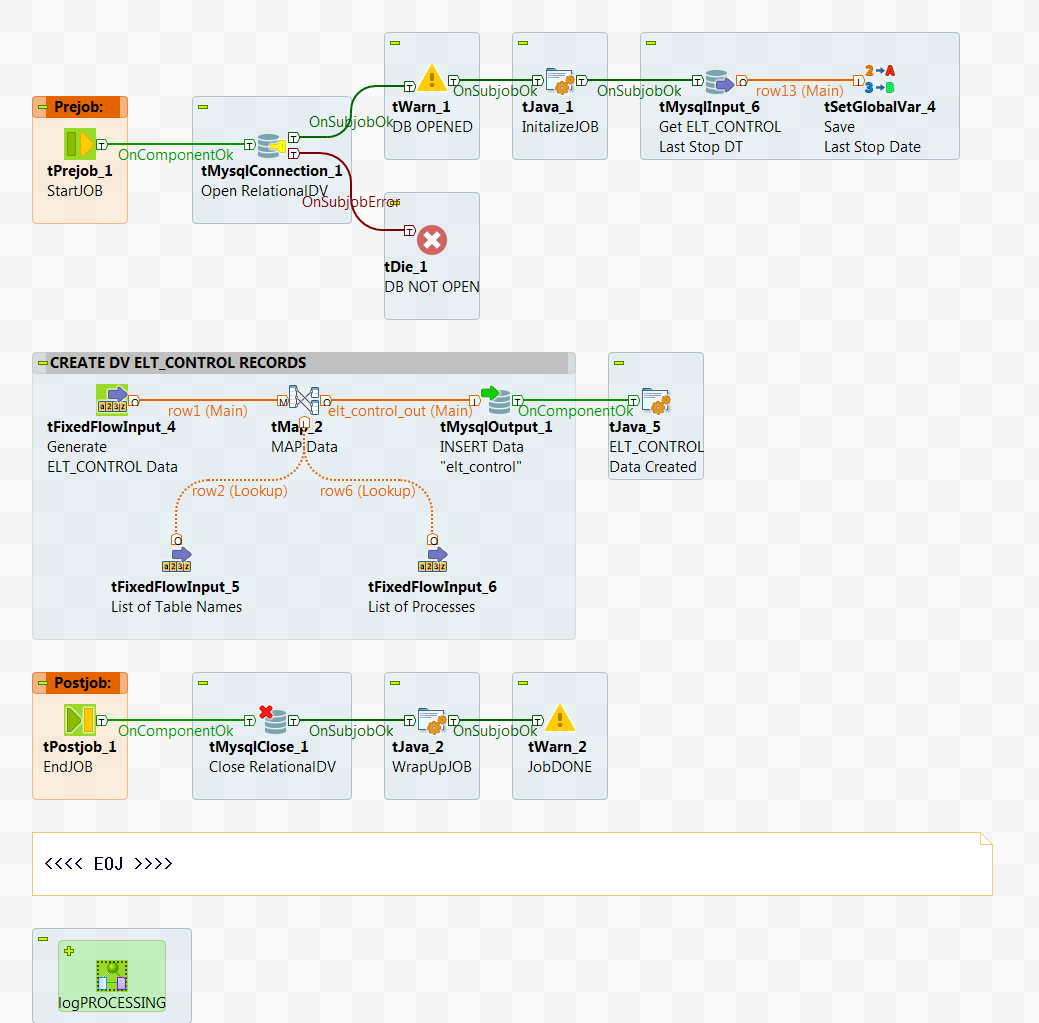
Run this Job! The TARGET ELT_CONTROL table should now have a fresh set of records to continue processing.
| RUN THE load_TARGET Job! |
This will create load the latest dump files into the DATA VAULT tables.
| RUN THE sync_ELT_DATAMART OR THE sync_ETL_DATAMART Job! |
This will add the latest Data Vault records into the de-normalized table updating the data version number appropriately.
SummaryThis Talend Data Vault Tutorial has been provided to demonstrate how to build a ETL data integration process using best practices, specific techniques, and as an example to others who may be ready to venture into this realm. While limited to a relational data model from end-to-end, as described above, processing data through a Data Vault can certainly be implemented on a big data ecosystem like Hadoop and column based Data Marts. In particular Data Vault 2.0 has been design to adapt to this new paradigm and Talend is leading the ETL/ELT, Spark, Data Quality, and Self-Service technology requirements involved in building an Enterprise Data Vault Warehouse!
Please feel free to add comments, questions, and/or points of interest to this article.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!