
Transforming messages to words
Procedure
-
Double-click the tModelEncoder component labeled Tokenize to
open its Component view. This component
tokenize the SMS messages into words.
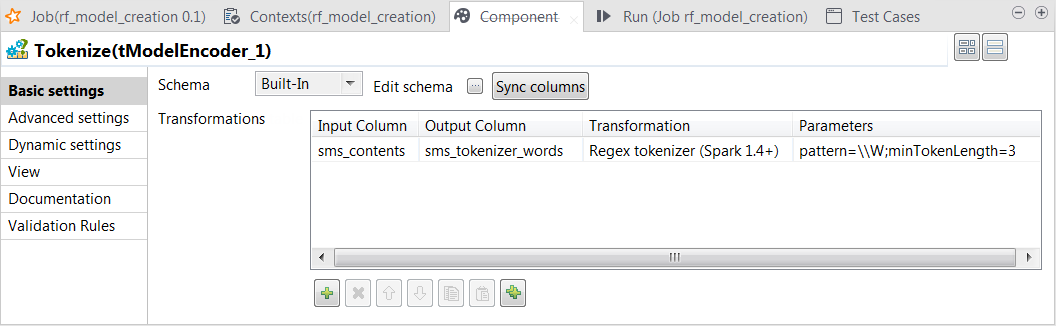
-
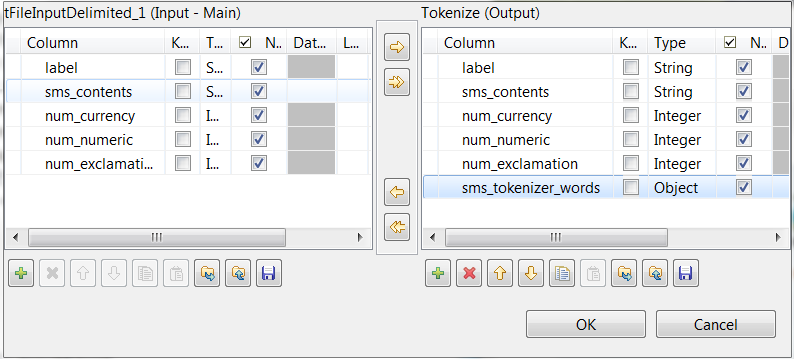
On the output side, click the [+] button to add one row and in the Column column, rename it to
sms_tokenizer_words. This column is used to carry the
tokenized messages.
Results
Using this transformation, tModelEncoder splits each input message by whitespace, selects only the words contains at least 3 letters and put the result of the transformation in the sms_tokenizer_words column. Thus currency symbols, numeric values, punctuations and words such as a, an or to are excluded from this column.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!