
Establishing the Job
Procedure
-
Connect the two components using a Row > Main connection.
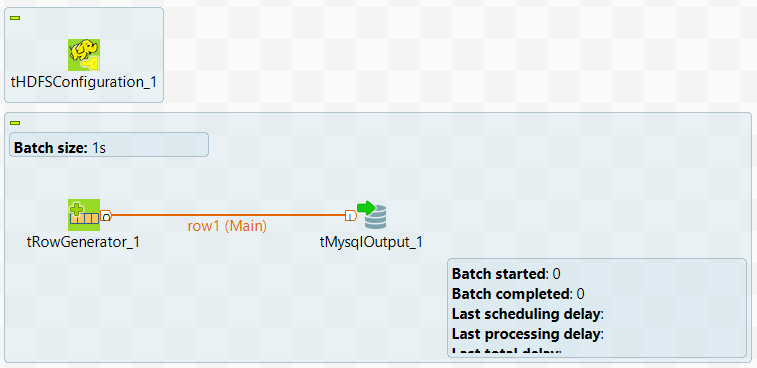
tHDFSConfiguration is used in this scenario by Spark to connect to the HDFS system where the jar files dependent on the Job are transferred.
In the Spark Configuration tab in the Run view, define the connection to a given Spark cluster for the whole Job. In addition, since the Job expects its dependent jar files for execution, you must specify the directory in the file system to which these jar files are transferred so that Spark can access these files:-
Yarn mode (Yarn client or Yarn cluster):
-
When using Google Dataproc, specify a bucket in the Google Storage staging bucket field in the Spark configuration tab.
-
When using HDInsight, specify the blob to be used for Job deployment in the Windows Azure Storage configuration area in the Spark configuration tab.
- When using Altus, specify the S3 bucket or the Azure Data Lake Storage for Job deployment in the Spark configuration tab.
-
When using on-premises distributions, use the configuration component corresponding to the file system your cluster is using. Typically, this system is HDFS and so use tHDFSConfiguration.
-
-
Standalone mode: use the configuration component corresponding to the file system your cluster is using, such as tHDFSConfiguration Apache Spark Batch or tS3Configuration Apache Spark Batch.
If you are using Databricks without any configuration component present in your Job, your business data is written directly in DBFS (Databricks Filesystem).
Prerequisite: ensure that the Spark cluster has been properly installed and is running.
-
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!