
Configuring the Job for aggregating values based on dynamic schema
Configure the Job to aggregate some task assignment data in a CSV file based on a dynamic schema column using the tAggregateRow component.
Then this Job displays the aggregated data on the console using the tLogRow component and writes it into an output CSV file using the tFileOutputDelimited component.
Procedure
-
Click the
 button next to Edit schema to
open the schema dialog box and define the schema by adding two columns, task of String type and other of Dynamic type. When done, click OK to save the changes and close the schema dialog box.
Note that the dynamic column must be defined in the last row of the schema. For more information about dynamic schema, see Dynamic schema.
button next to Edit schema to
open the schema dialog box and define the schema by adding two columns, task of String type and other of Dynamic type. When done, click OK to save the changes and close the schema dialog box.
Note that the dynamic column must be defined in the last row of the schema. For more information about dynamic schema, see Dynamic schema. -
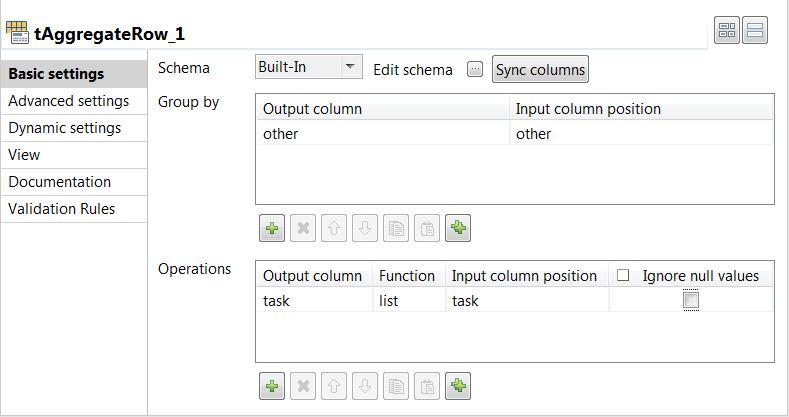
Double-click the tAggregateRow
component, and on its Basic settings view, click
the Sync columns button to retrieve the schema from
the preceding component.
-
Add one row in the Group by table by
clicking the
 button below it, and select other from both the Output column
and Input column position column fields to group
the input data by the other dynamic
column.
Note that the dynamic column aggregation can be carried out only for the grouping operation.
button below it, and select other from both the Output column
and Input column position column fields to group
the input data by the other dynamic
column.
Note that the dynamic column aggregation can be carried out only for the grouping operation.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!