
Denormalizing on multiple columns
Procedure
-
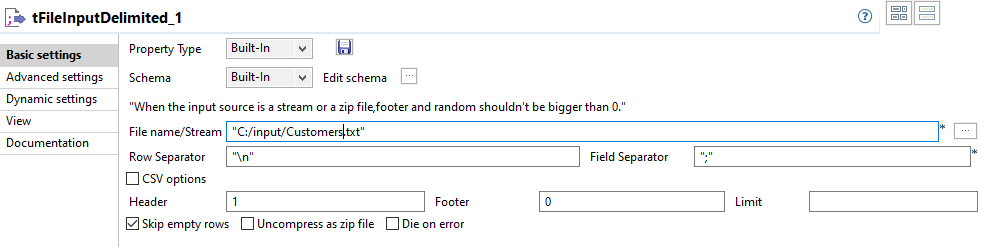
On the tFileInputDelimited
Basic settings panel, set the filepath to
the file to be denormalized.
-
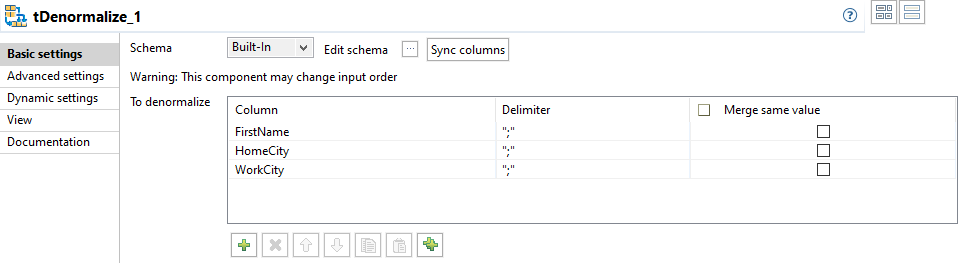
Click the
 to add rows and define the columns to denormalize.
to add rows and define the columns to denormalize.
-
In the Delimiter column,
define the separator between double quotes, to split concatenated values.
Results
|=-----+---------+-----------------------+------------------------------=|
|Name |FirstName|HomeCity |WorkCity |
|=-----+---------+-----------------------+------------------------------=|
|Joli |Angelina |Berlin;Los Angeles |Berlin;Los Angeles |
|Moore |Demi |New York;Rio de Janeiro|Paris;Los Angeles |
|Willis|Bruce |Paris;Madrid;Roma |Los Angeles;Madrid;Paris;Dublin|
|Pitt |Brad |Berverly Hills;Paris |Los Angeles;London |
'------+---------+-----------------------+-------------------------------'Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!