
Cleaning up and filtering a CSV file
This Job searches and replaces various typos and defects in a csv file then operates a column filtering before producing a new csv file with the final output.
-
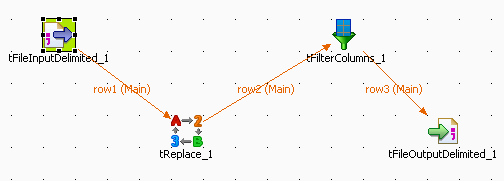
Drop the following components from the Palette onto the design workspace: tFileInputDelimited, tReplace, tFilterColumn and tFileOutputDelimited.
-
Connect the components using Main Row connections via a right-click each component.
-
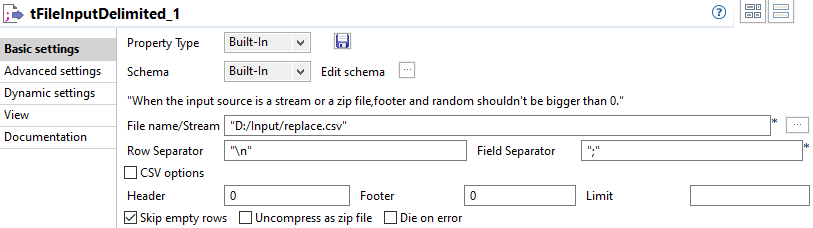
Select the tFileInputDelimited component and set the input flow parameters.
-
The File is a simple csv file stored locally. The Row Separator is a carriage return and the Field Separator is a semi-colon. In the Header is the name of the column, and no Footer nor Limit are to be set.
-
The file contains characters such as: *t, . or Nikson which we want to turn into Nixon, and streat, which we want to turn into Street.

-
The schema for this file is built in also and made of four columns of various types (string or int).
-
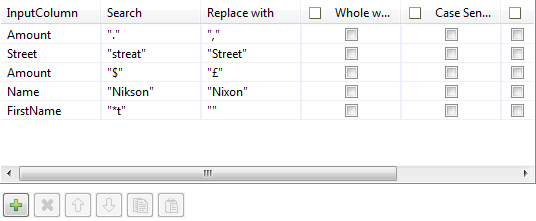
Now select the tReplace component to set the search & replace parameters.
-
The schema can be synchronized with the incoming flow.
-
Select the Simple mode check box as the search parameters can be easily set without requiring the use of regexp.
-
Click the plus sign to add some lines to the parameters table.
-
On the first parameter line, select Amount as InputColumn. Type "." in the Search field, and "," in the Replace field.
-
On the second parameter line, select Street as InputColumn. Type "streat" in the Search field, and "Street" in the Replace field.
-
On the third parameter line, select again Amount as InputColumn. Type "$" in the Search field, and "£" in the Replace field.
-
On the fourth paramater line, select Name as InputColumn. Type "Nikson" in the Search field, and "Nixon" in the Replace field.
-
On the fifth parameter line, select Firstname as InputColumn. Type "*t" in the Search field, and replace them with nothing between double quotes.
-
The advanced mode isn't used in this scenario.
-
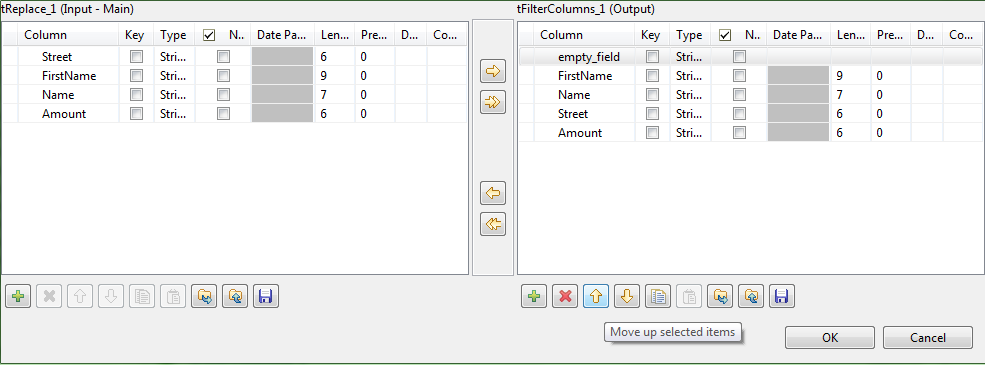
Select the next component in the Job, tFilterColumn.
-
The tFilterColumn component holds a schema editor allowing to build the output schema based on the column names of the input schema. In this use case, add one new column named empty_field and change the order of the input schema columns to obtain a schema as follows: empty_field, Firstname, Name, Street, Amount.
-
Click OK to validate.
-
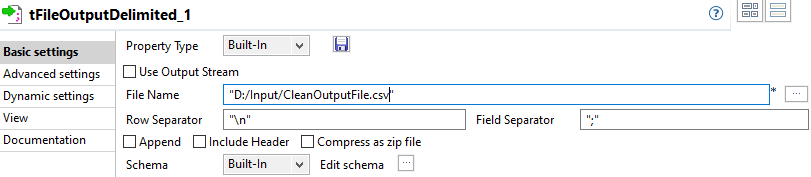
Set the tFileOutputDelimited properties manually.
-
The schema is built-in for this scenario, and comes from the preceding component in the Job.
-
Save the Job and press F6 to execute it.
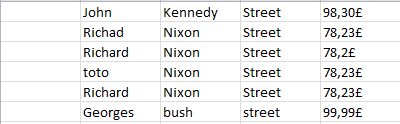
The first column is empty, the rest of the columns have been cleaned up from the parasitical characters, and Nikson was replaced with Nixon. The street column was moved and the decimal delimiter has been changed from a dot to a comma, along with the currency sign.