
Configuring the input data
The tFileInputDelimited components are configured to load data from DBFS
into the Job.
Before you begin
-
The source files, movies.csv and directors.txt have been uploaded into DBFS as explained in Uploading files to DBFS (Databricks File System).
-
The metadata of the movie.csv file has been set up under the File delimited node in the Repository.
If you have not done so, see Preparing the movies metadata to create the metadata.
Procedure
-
Double-click this schema metadata node to open its
wizard.
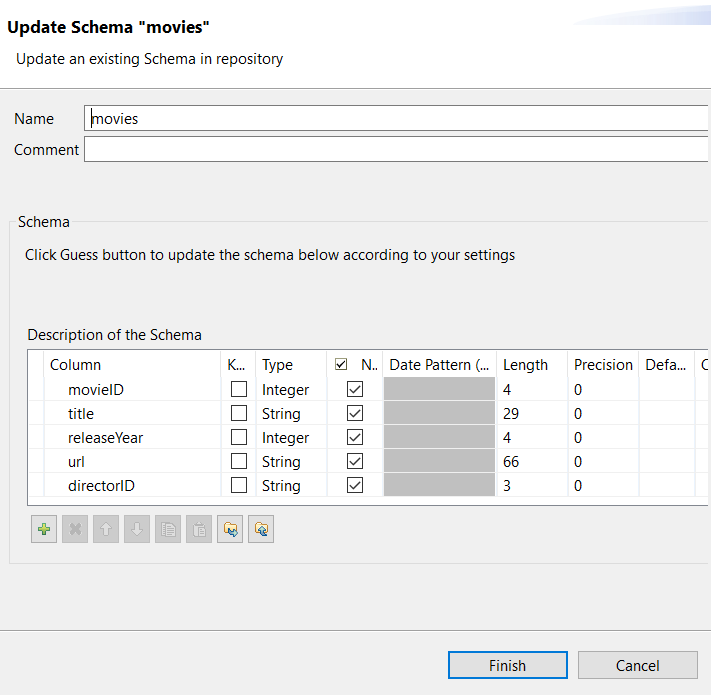
-
Click the
 button to export the schema to a
local directory.
button to export the schema to a
local directory.
-
Double-click the movie
tFileInputDelimited
component to open its Component view.
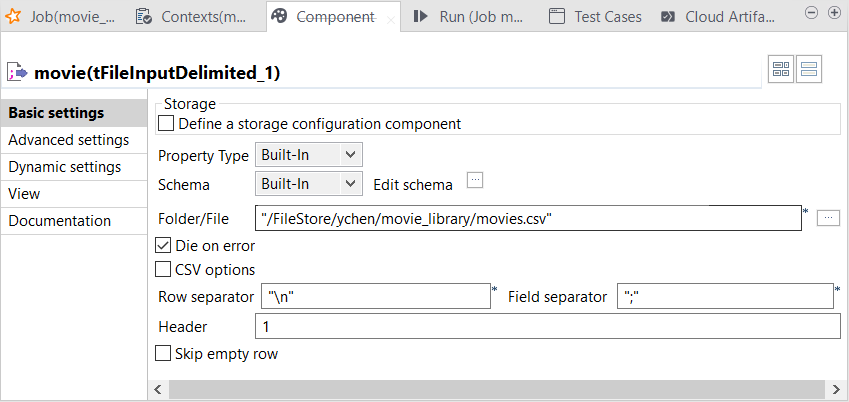
-
Click Edit schema to open the editor of the schema and
click the
 button to import
the schema of the movie data you exported previously from the File
delimited metadata in Repository.
button to import
the schema of the movie data you exported previously from the File
delimited metadata in Repository.
-
Double-click the director
tFileInputDelimited component to open its Component view.
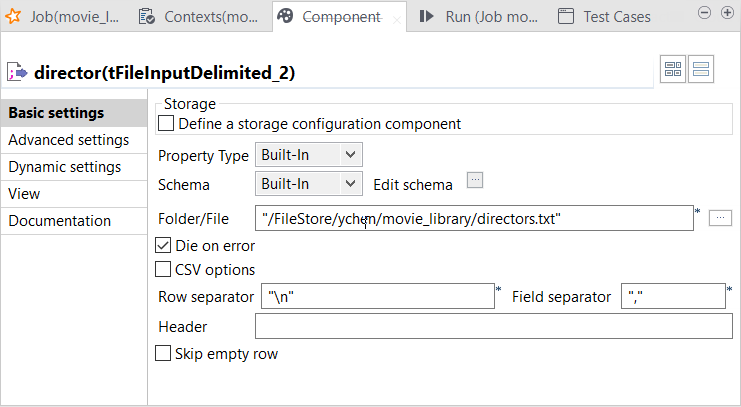
-
Click the [+] button twice to add two rows and in
the Column column, rename them to ID and Name, respectively.
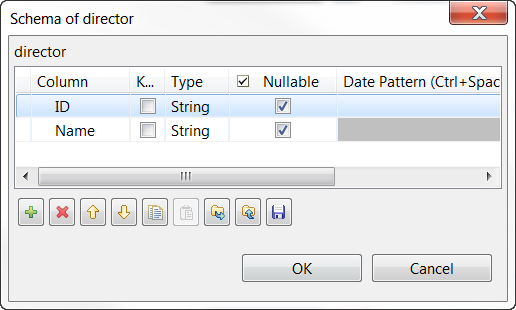
Results
The input components are now configured to load the movie data and the director data to the Job.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!