
Creating a connection to MapR-DB
Procedure
-
Click Finish to validate the changes.
The newly created MapR connection appears under the Hadoop cluster node of the Repository tree. In addition, as a MapR-DB connection is a database connection, this new connection appears under the Db connections node, too.
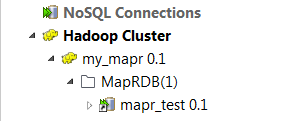
Results
-
Create a new repository context: create this environmental context out of the current Hadoop connection, that is to say, the parameters to be set in the wizard are taken as context variables with the values you have given to these parameters.
-
Reuse an existing repository context: use the variables of a given environmental context to configure the current connection.
For a step-by-step example about how to use this Export as context feature, see Exporting metadata as context and reusing context parameters to set up a connection.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!