
What is a Joblet
A Joblet is a specific component that replaces Job component groups. It factorizes recurrent processing or complex transformation steps to ease the reading of a complex Job. Joblets can be reused in different Jobs or several times in the same Job.
At runtime, the Joblet code is integrated into the Job code itself. No separate code is generated, the same Java class being used.
This way, the Joblet use does not have any drawbacks on the performance side. The execution time is unchanged whether your Job includes a Joblet or the whole subJob directly.
Moreover if you intend to log and monitor the whole Job statistics and execution error or warnings, the Joblets included in your Job will be monitored without requiring further log component (such as tLogCatcher, tStatCatcher or tFlowCatcher).
A Joblet is easily identified as it is enclosed in a dotted square on a green background.
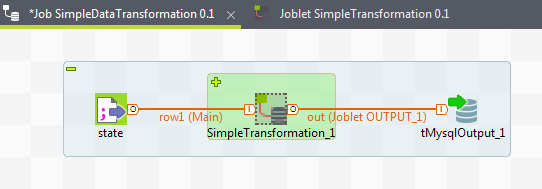
This specific component can be used like any other usual component in a Job. For more information on how to design a Job, see What is a Job design?.
- a Standard Job supports the Standard Joblets only
- a Spark Job supports the Spark Joblets only
Unlike for the tRunJob component, the Joblet code is automatically included in the Job code at runtime, thus using less resources. As it uses the same context variables as the Job itself, the Joblet is easier to maintain.
To use a group of components as a standalone Job, you can use the tRunJob component. Unlike the Joblet, the tRunJob has its own context variables.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!