
What you need to know about some databases
Google BigQuery
Profiling data from Google BigQuery requires to go through a JDBC connection setting.
For more information, see how to build the Connection URL.
The RECORD data type is not supported.
When you set up a JDBC connection, specify each jar file extracted from the zip file.
Hive
- Go to the Hive server configuration.
- Set the HiveServer2 Java Heap Size parameter to at least 1 GB.
If you select to connect to the Hive database, you will be able to create and execute different analyses as with the other database types.
In the connection wizard, you must select from the Distribution list the platform that hosts Hive. You must also set the Hive version and model.
For more information, see Apache Hadoop documentation.
If you decide to change the username in an embedded mode of a Hive connection, you must restart Talend Studio before being able to successfully run the profiling analyses that use the connection.
- Click the button next to Hadoop Properties and in the open dialog box click the [+] button to add two lines to the table.
- Enter the parameters names as mapred.job.map.memory.mb and mapred.job.reduce.memory.mb.
-
Set their values to the by-default value 1000.
This value is normally appropriate for running the computations.
| Unsupported indicators | Unsupported functions | Unsupported analyses |
|---|---|---|
| With SQL engine: Soundex Low Frequency Pattern(Low) Frequency Upper Quartile and Lower Quartile Median All Date Frequency indicators |
|
The only analysis that is not supported for Hive is Time Correlation Analysis as the Date data type does not exist in Hive. For further information on this analysis type, see Time correlation analyses. |
All right-click options on analysis results that generate Jobs to validate, standardize, and deduplicate data are not supported for Hive. For further information about these Jobs, see Validating data.
Hive and HBase
When you select to connect to a Hive or a HBase database to create and execute different analyses, then in the connection wizard, you must, as explained above, select from the Distribution contextual menu list the platform that hosts Hive or HBase.
- The parameter is yarn.application.classpath
- The value is /etc/hadoop/conf,/usr/lib/hadoop/,/usr/lib/hadoop/lib/,/usr/lib/hadoop-hdfs/,/usr/lib/hadoop-hdfs/lib/,/usr/lib/hadoop-yarn/,/usr/lib/hadoop-yarn/lib/,/usr/lib/hadoop-mapreduce/,/usr/lib/hadoop-mapreduce/lib/
Microsoft SQL Server
Microsoft SQL Server 2012 and later are supported.
If you select to connect to the Microsoft SQL Server database with Windows Authentication Mode, you can select Microsoft or JTDS open source from the Db Version list.
When using a Microsoft SQL Server database to store report results, both Microsoft JDBC and JTDS open source drivers are supported.
If you are creating a connection to Azure SQL Database to store reports and analysis results, enter ssl=require in the Additional parameters field of the database connection settings.
- Download the JTDS driver version 1.3.1 from JTDS website.
- Extract the files from the archive and copy the ntlmauth.dll file under x64/SSO or x86/SSO, according to your operating system.
- Paste the ntlmauth.dll file to %SYSTEMROOT%/system32
If you encounter the following error: SSO Failed: Native SSPI library not loaded, paste the ntlmauth.dll to the bin directory of the JRE used by Talend Studio.
The collation used by the Microsoft SQL Server database must be case-insensitive, otherwise the report generation may not succeed. You may encounter errors like java.sql.SQLException: Invalid column name 'rep_runtime'. For more information about collation rules, see Windows Collation Name.
The ntext data type is not supported.
MySQL
When creating a connection to MySQL via JDBC, it is not mandatory to include the database name to the JDBC URL. Regardless of whether the database connection URL specified in the JDBC URL field includes the database name, all databases are retrieved.
For example, if you specify jdbc:mysql://192.168.33.41:3306/tbi?noDatetimeStringSync=true, where tbi is the database name, or jdbc:mysql://192.168.33.41:3306/?noDatetimeStringSync=true, all databases are retrieved.
To support surrogate pairs in data and metadata, you need to edit the following properties in the MySQL server configuration file:
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
character-set-server=utf8mb4Netezza
The Netezza database does not support regular expressions. If you want to use regular expressions with this database, you must:
- Install the SQL Extensions Toolkit package on a Netezza system. Use the regex_like function provided in this toolkit in the SQL template as documented in IBM Netezza SQL Extensions toolkit installation and setup.
- Add the indicator definition for Netezza in the Pattern
Matching directory in Talend Studio
under .
The query template you need to define for Netezza is as the following: SELECT COUNT(CASE WHEN REGEXP_LIKE(<%=COLUMN_NAMES%>,<%=PATTERN_EXPR%>) THEN 1 END), COUNT FROM <%=TABLE_NAME%><%=WHERE_CLAUSE%>.
Oracle
To support surrogate pairs, the NLS_CHARACTERSET parameter of the database must be set to UTF8 or AL32UTF8.
The default NLS_CHARACTERSET parameters are:
- NLS_CHARACTERSET=WE8ISO8859P15
- NLS_NCHAR_CHARACTERSET=AL16UTF16
Oracle Custom
To connect to an Oracle database using Oracle Custom as the DB Type, select the Use SSL Encryption and Need Client Authentication check boxes and fill in the Trust Store Path and Trust Store Password fields.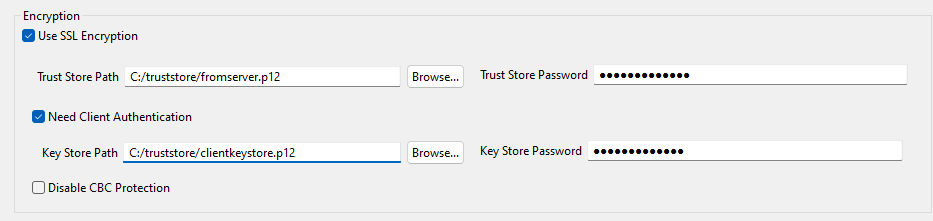
PostgreSQL
When you connect to a PostgreSQL database via a JDBC connection, the INT4 and INT8 data types are replaced by a String data type. As a consequence, if your analysis uses the T-Swoosh algorithm, the survivorship functions are for strings, not for numbers.
- Close the analysis and switch to the Integration perspective.
- Expand Metadata and right-click the database connection.
- Select the check box of the table to update.
- When Creation status is set to Success, click Next.
- If columns with no database type must be of Integer type, set DB Type to INT.
- Click Finish and close the dialog box.
- Switch to the Profiling perspective and open the analysis.
- In Survivorship Rules for Columns, delete and add back the columns you updated. You can see the survivorship functions for numbers (Largest and Smallest).
SAP HANA
Profiling data from SAP HANA is only possible for Table, View, and Calculation View schemas.
The Soundex frequency statistics indicators support the English alphabet only.
Snowflake
Profiling data from Snowflake requires a JDBC connection.
When the table name and the structure are identical, you can switch contexts to switch databases and schemas. Switching catalogs or schemas is based on the JDBC URL. After you switched the contexts, only the catalog or schema from the URL is displayed under the connection node.
For more information, see Configuring the JDBC Driver.
You cannot use a connection created under the Snowflake node in the Integration perspective.
Teradata
If you select to connect to the Teradata database, select the Yes option next to USE SQL Mode to enable Talend Studio to use the SQL queries to retrieve metadata. The JDBC driver is not recommended with this database because of possible bad performance.
In the Teradata database, the regular expression function is installed by default only starting from version 14. If you want to use regular expressions with older versions of this database, you must install a User Defined Function in Teradata and add the indicator definition for Teradata in Talend Studio.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!