
Configuring the input component
Before you begin
You downloaded the tJapaneseTokenize_standard_scenario.zip file.
Procedure
-
Double-click tFileInputDelimited to open its
Basic settings view in the
Component tab.
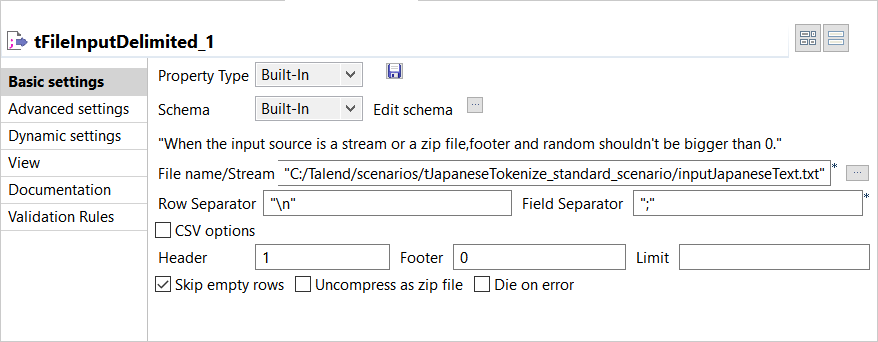
-
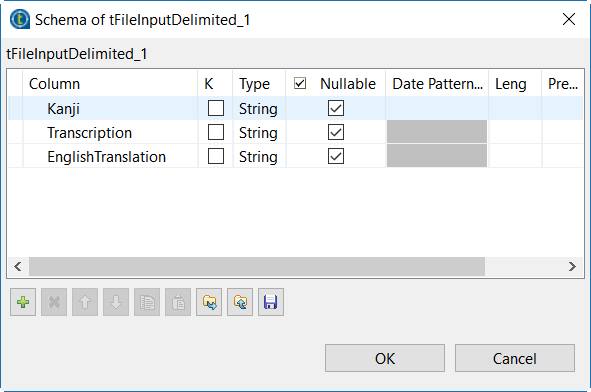
Click the [+] button to add the schema columns.
Example
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!