
Fixing the issues with Talend Cloud Data Preparation
You are now a data analyst from the finance department, tasked with investigating the
poor quality of the customers_billing_dataset dataset that you have
been given access to. You will look at the data itself and create a new
preparation.
Procedure
-
From the Dataset list, click
customers_billing_dataset to open the detailed view
of the dataset.
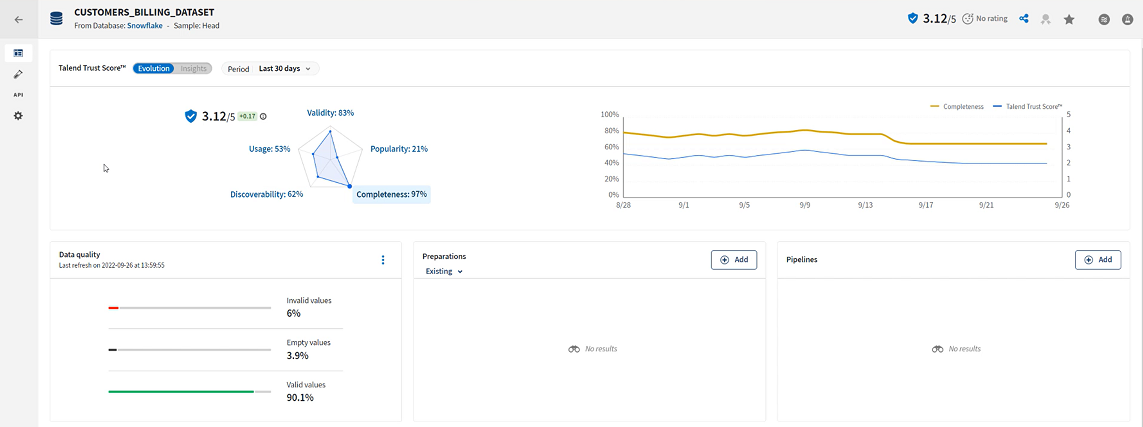
You can already get a sense of the dataset, with the Talend Trust Score™ diagram showing a downward trend in the last few days, which means that the latest data added to the database contains errors. This is confirmed by the Data quality tile showing a certain percentage of invalid and empty values.
-
To take a look at the data itself, click the Sample icon
from the left menu.
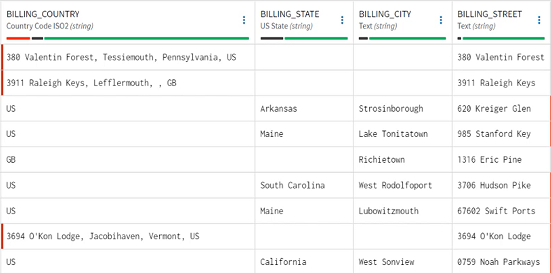
The data is displayed in a grid view. You can quickly see discrepancies between valid and invalid values in certain columns, and most noticeably, you notice that the Billing_Country column contains full addresses that should have been split between several columns.
-
To start a new preparation on this dataset and fix these errors, click the button on the top right of the screen.
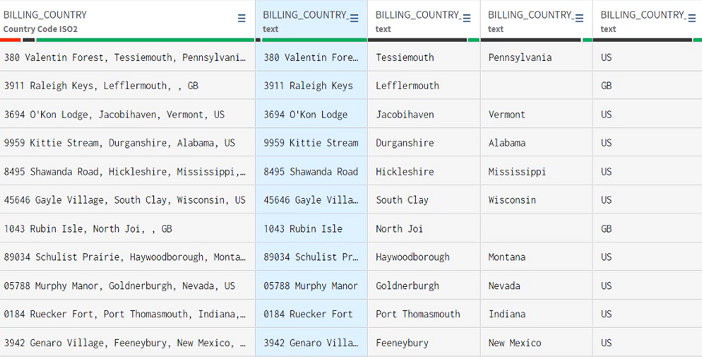
Talend Cloud Data Preparation opens and you can now start applying transformation operations on the data sample.
Results
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!