
Discovering semantic types
The data discovery calculates how many values match each semantic type and, if the result is greater than 40%, it assigns the semantic type to the column.
To display the percentage for each semantic type, in the sample view of your dataset,
click the ![]() icon.
icon.
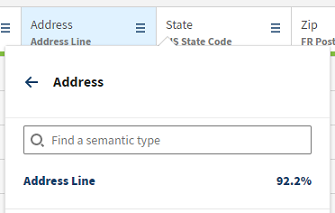
This feature is also available from the Hierarchy view.
How is the percentage calculated?
-
One percentage represents the number of values
matching the semantic type; up to 100% allocated.
To determine if a value matches a semantic type, the data discovery depends on the type of the semantic type:
- Dictionary: Does the value match a value from the dictionary? Punctuation, case, spaces, and accents are ignored.
- Regular expression: Does the value match the regular expression?
- Compound: is the value discovered into at
least one child?A compound type is a group of existing semantic types, called children.
If the answer is positive, the value is considered valid.
- The other percentage represents the
similarity between the column name and the name of the semantic type; up to 10%
allocated. To compare the names:The maximum percentage is 100%. If all values match a semantic type and the column name is identical to the name of the semantic type, the result still is 100%.
- The Levenshtein algorithm is used. It calculates the minimum number of edits (insertion, deletion, or substitution) required to transform one string into another.
- The case and accents are ignored.
- If the strings contain spaces, the word order is ignored. For example, US Phone and Phone US are considered identical.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!