
Using context variables to use different connection strings at execution time
In this scenario context variables are added to override the connection credentials and thus to switch between a pre-Production database and a Production database at execution time.
Before you begin
-
You have previously created a connection to the system storing your source data, here a MySQL connection.
-
You have previously added the dataset holding your source data.
Here, a table containing contact data including customer identifiers, names, addresses, countries, credit limits, etc.
- You also have created the destination connection, here a Test dataset where you will store output logs.
Procedure
-
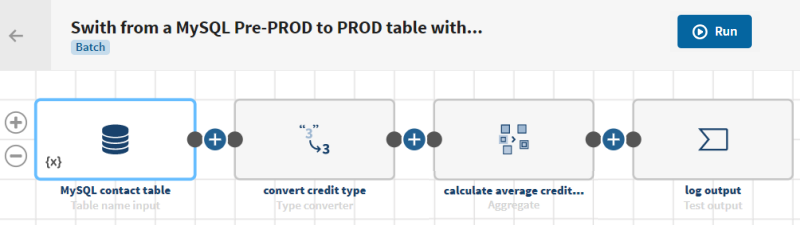
Click ADD SOURCE to
open the panel allowing you to select your source data, here MySQL contact table. A sample of your data is
displayed in the preview panel.
-
Click
 and add a Type converter processor to the pipeline.
The Configuration panel opens.
and add a Type converter processor to the pipeline.
The Configuration panel opens.
-
Click and
add an Aggregate processor to the
pipeline. The Configuration panel opens.
-
Click Save to
save your configuration.
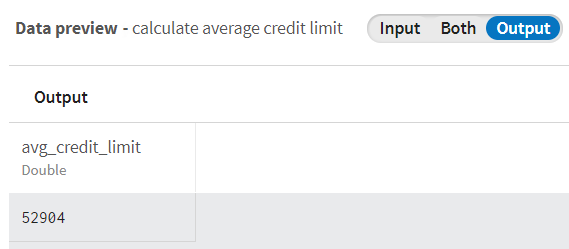
You can see that the records about credit limits are converted to a Double type.
-
(Optional) If you execute your pipeline at this stage, you
will see in the logs that:
- the pipeline was successfully executed and 52 records have been read.
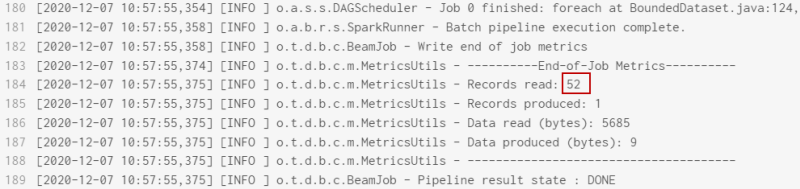
- no context variables were set in this pipeline.

- the pipeline was successfully executed and 52 records have been read.
-
Go back to the Connection tab of the MySQL contact
table source to add and assign a variable:
-
Click the
 icon next to the JDBC URL parameter to open the
[Add a variable]
window.
icon next to the JDBC URL parameter to open the
[Add a variable]
window.
-
Click Save to
save your configuration.
Once the variable is assigned, the
 icon will be displayed to indicate that a variable has been set in
the pipeline.
icon will be displayed to indicate that a variable has been set in
the pipeline.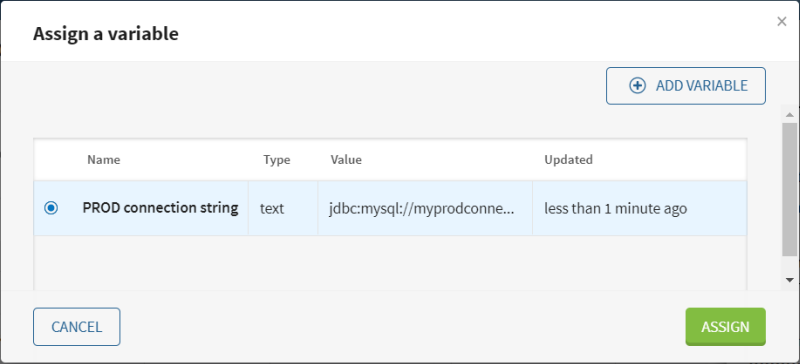
-
Click the
Results
- In the pipeline execution logs, you can see that a higher number of records have
been read (1153).
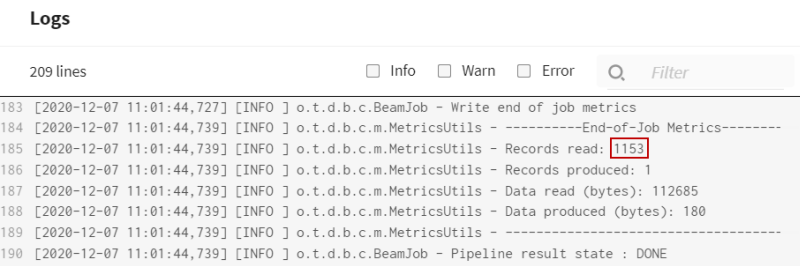
- You can also see the context variable value used to retrieve the data from the
Production table at execution time.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!