
Configurer les données d'entrée
Les composants tFileInputDelimited sont configurés pour charger des données de DBFS dans le Job.
Avant de commencer
-
Les fichiers sources, movies.csv et directors.txt doivent avoir été chargés dans DBFS, comme expliqué dans Charger des fichiers dans DBFS (Databricks File System).
-
la métadonnée du fichier movie.csv a été configurée sous le nœud File delimited, dans le Repository.
Si ce n'est pas le cas, consultez Préparer la métadonnée relative aux films pour créer la métadonnée.
Procédure
-
Double-cliquez sur le nœud de cette métadonnée de schéma pour ouvrir son assistant.
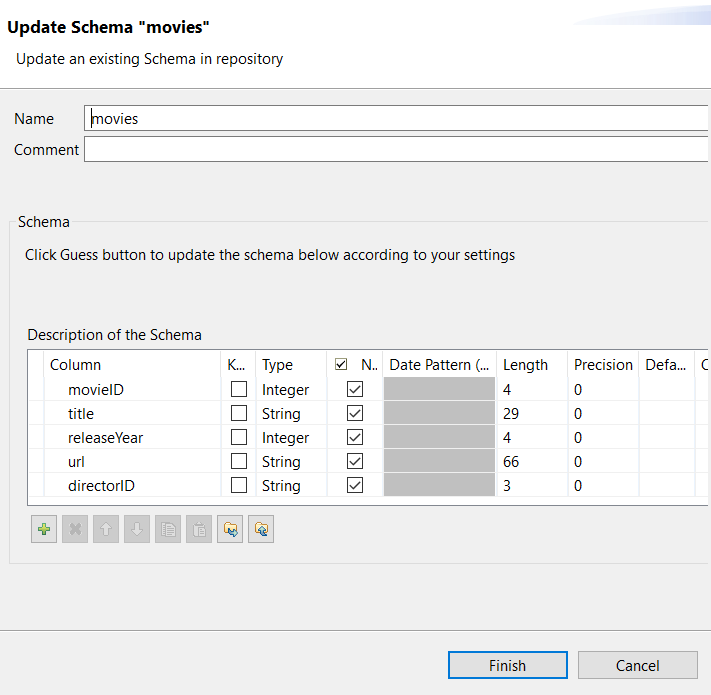
-
Cliquez sur le bouton
 pour exporter le schéma vers un répertoire local.
pour exporter le schéma vers un répertoire local.
-
Double-cliquez sur le composant movie tFileInputDelimited pour ouvrir sa vue Component.
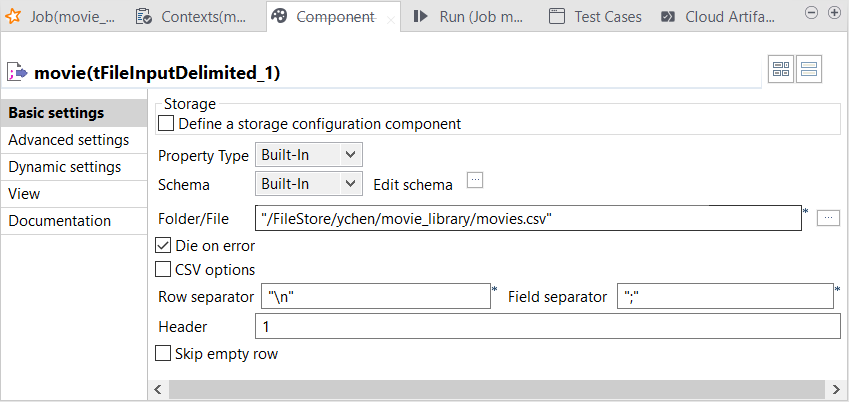
-
Cliquez sur Edit schema pour ouvrir l'éditeur du schéma, puis cliquez sur le bouton
 pour importer le schéma des données de films précédemment exporté depuis la métadonnée File delimited dans le Repository.
pour importer le schéma des données de films précédemment exporté depuis la métadonnée File delimited dans le Repository.
-
Double-cliquez sur le composant tFileInputDelimited nommé director pour ouvrir sa vue Component.
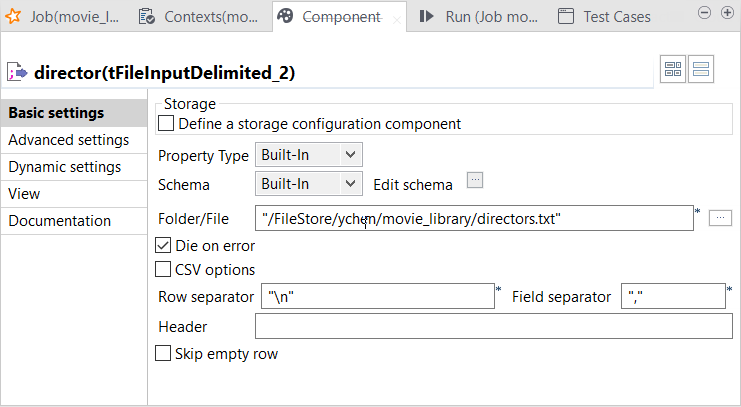
-
Cliquez deux fois sur le bouton [+] pour ajouter deux lignes et, dans la colonne Column, renommez-les respectivement en ID et Name.
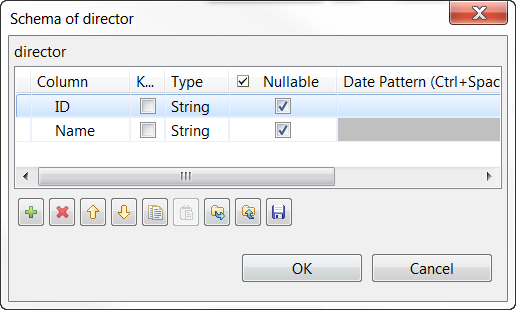
Résultats
Les composants d'entrée sont configurés pour charger les données des films et cinéastes dans le Job.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !