
Configurer manuellement la connexion
Pourquoi et quand exécuter cette tâche
Même si l'import d'une configuration Hadoop donnée est efficace, il est possible que vous deviez configurer manuellement la connexion, dans certaines circonstances, par exemple si vous n'avez pas les configurations à importer sous la main.
Procédure
-
Renseignez les champs disponibles selon la version sélectionnée.
Notez que, parmi ces champs, les champs NameNode URI et Resource Manager) ont été automatiquement renseignés avec la syntaxe par défaut et le numéro de port correspondants à la distribution sélectionnée. Vous devez mettre à jour uniquement la partie dont vous avez besoin, selon la configuration du cluster Hadoop à utiliser. Pour plus d'informations concernant les différents champs à utiliser, consultez la liste suivante.
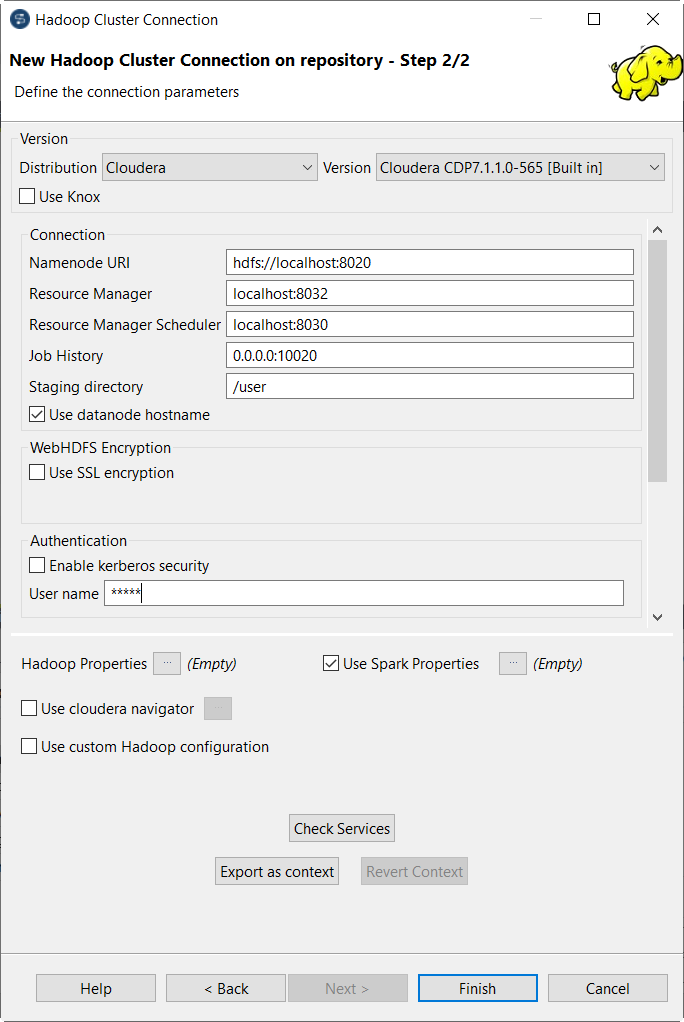 Les champs peuvent être :
Les champs peuvent être :-
Namenode URI :
Saisissez l'URI pointant vers la machine utilisée comme NameNode de la distribution Hadoop à utiliser.
Le NameNode est le nœud principal d'un système Hadoop. Par exemple, si vous avez choisi une machine nommée machine1 comme NameNode d'une distribution Apache Hadoop, l'emplacement à saisir est hdfs://machine1:portnumber.
Si vous utilisez WebHDFS, l'emplacement doit être webhdfs://masternode:portnumber ; WebHDFS avec SSL n'est pas supporté.
Si vous utilisez une distribution MapR, vous pouvez simplement laisser maprfs:/// dans le champ. Le client MapR va gérer les informations à la volée lors de la création de la connexion. Le client MapR doit être correctement installé. Pour plus d'informations concernant l'installation et la configuration de votre client MapR, consultez la documentation MapR (en anglais).
-
Resource Manager :
Saisissez l'URI pointant vers la machine utilisée comme service du gestionnaire de ressources (Resource Manager) de la distribution Hadoop à utiliser.
Notez que, dans certaines anciennes versions des distributions Hadoop, vous devez configurer l'emplacement du service du JobTracker au lieu du service du gestionnaire de ressources.
Vous devez configurer les adresses des services relatifs, comme l'adresse du Resourcemanager scheduler. Lorsque vous utilisez cette connexion dans un composant Big Data, comme le tHiveConnection, vous pouvez allouer de la mémoire aux calculs Map et Reduce et à l'ApplicationMaster de YARN dans la vue Advanced settings. Pour plus d'informations concernant le Resource Manager, son ordonnanceur et son ApplicationMaster, consultez la documentation de YARN (en anglais) pour votre distribution.
-
Job history :
Saisissez l'emplacement du serveur de JobHistory du cluster Hadoop à utiliser. Cela permet de stocker les métriques du Job courant sur le serveur de JobHistory.
-
Staging directory :
Saisissez le répertoire défini dans votre cluster Hadoop pour les fichiers temporaires créés par les programmes en cours d'exécution. Généralement, ce répertoire se trouve sous la propriété yarn.app.mapreduce.am.staging-dir dans les fichiers de configuration comme yarn-site.xml ou mapred-site.xml de votre distribution.
-
Use Datanode hostname :
Cochez cette case pour permettre au Job d'accéder aux nœuds de données (datanodes) via leurs noms d'hôtes. Cela permet de configurer la propriété dfs.client.use.datanode.hostname à true. Si cette connexion doit être utilisée par un Job se connectant à un système de fichiers S3N, cochez cette case.
-
Enable Kerberos security :
Si vous accédez à une distribution Hadoop s'exécutant avec la sécurité Kerberos, cochez cette case, puis saisissez les noms des Principaux de Kerberos pour le NameNode dans le champ activé.
Ces principaux se trouvent dans les fichiers de configuration de votre distribution. Par exemple, dans une distribution CDH4, le principal du gestionnaire de ressource est configuré dans le fichier yarn-site.xml et le principal de l'historique des Jobs dans le fichier mapred-site.xml.
Si vous devez utiliser un fichier Keytab pour vous identifier, cochez la case Use a keytab to authenticate. Un fichier Keytab contient les paires des Principaux et clés cryptées Kerberos. Vous devez saisir le Principal à utiliser dans le champ Principal. Dans le champ Keytab, parcourez votre système jusqu'au fichier Keytab à utiliser.
l'utilisateur ou l'utilisatrice exécutant un Job utilisant un fichier Keytab n'est pas nécessairement celui désigné par un Principal mais doit avoir le droit de lire le fichier Keytab utilisé. Par exemple, le nom d'utilisateur ou d'utilisatrice que vous utilisez pour exécuter le Job est user1 et le principal à utiliser est guest. Dans cette situation, assurez-vous que user1 a les droits de lecture pour le fichier Keytab à utiliser.
-
Si vous vous connectez à un cluster MapR V4.0.1 ou supérieure et que le système de sécurité de votre cluster par ticket MapR est activé, vous devez cocher la case Force MapR Ticket Authentication et configurer les paramètres suivants :
- Dans le champ Password, spécifiez le mot de passe utilisé pour l'authentification de l'utilisateur ou de l'utilisatrice.
Un ticket de sécurité MapR est généré pour cet·te utilisateur·rice par MapR et stocké dans la machine où est exécuté le Job que vous configurez.
- Dans le champ Cluster name, saisissez le nom du cluster MapR auquel vous souhaitez que l'utilisateur ou l'utilisatrice se connecte.
Le nom du cluster se trouve dans le fichier mapr-clusters.conf situé dans le dossier /opt/mapr/conf du cluster.
- Dans le champ Ticket duration, saisissez la durée du temps (en secondes) durant laquelle le ticket est valide.
- Laissez la case Launch authentication mechanism when the Job starts cochée afin d'assurer que le Job utilisant cette connexion prend en compte la configuration actuelle de sécurité lorsqu'il commence à s'exécuter.
Si la configuration de la sécurité par défaut de votre cluster MapR a été modifiée, vous devez configurer la connexion pour qu'elle prenne en compte cette configuration personnalisée de la sécurité.
MapR spécifie sa configuration de sécurité dans le fichier mapr.login.conf situé dans le dossier /opt/mapr/conf du cluster. Pour plus d'informations concernant ce fichier de configuration et les services Java qu'il utilise, consultez la documentation MapR et JAAS (pages en anglais).
Procédez comme suit pour configurer :
- Vérifiez ce qui a été modifié dans le fichier mapr.login.conf.
Vous devriez pouvoir obtenir les informations relatives de l'administrateur ou du développeur de votre cluster MapR.
- Si l'emplacement de vos fichiers de configuration MapR a été modifié dans le cluster, c'est-à-dire si le répertoire Home MapR a été modifié cochez la case Set the MapR Home directory et saisissez le nouveau répertoire Home. Sinon, laissez la case décochée, pour utiliser le répertoire Home par défaut.
- Si le module de connexion à utiliser a été modifié dans le fichier mapr.login.conf, cochez la case Specify the Hadoop login configuration et saisissez le module à appeler depuis le fichier mapr.login.conf. Sinon, laissez décochée cette case pour utiliser le module d'authentification par défaut.
Par exemple, saisissez kerberos pour appeler le module hadoop_kerberos ou hybrid pour appeler le module hadoop_hybrid.
- Dans le champ Password, spécifiez le mot de passe utilisé pour l'authentification de l'utilisateur ou de l'utilisatrice.
-
User name :
Saisissez le nom d'authentification de l'utilisateur ou de l'utilisatrice de la distribution Hadoop à utiliser.
Si vous laissez ce champ vide, le Studio Talend utilise votre identifiant à la machine client sur laquelle vous travailler, pour accéder à la distribution Hadoop. Par exemple, si vous utilisez le Studio Talend sur une machine Windows et que votre identifiant est Company, l'identifiant utilisé lors de l'exécution est Company.
-
Group :
Saisissez le nom du groupe auquel l'utilisateur ou l'utilisatrice authentifié appartient.
Notez que ce champ est activé selon la distribution que vous utilisez.
-
Hadoop properties :
Si vous devez utiliser une configuration personnalisée pour la distribution Hadoop à utiliser, cliquez sur le bouton [...] pour ouvrir la table des propriétés et ajouter la ou les propriété(s) à personnaliser. Lors de l'exécution, les propriétés personnalisées écrasent celles par défaut utilisées par le Studio Talend pour son moteur Hadoop.
Notez que les propriétés définies dans cette table sont héritées et réutilisées par les connexions enfants que vous pouvez créer à partir de cette connexion Hadoop.
Pour plus d'informations concernant les propriétés Hadoop, consultez la documentation Apache Hadoop (en anglais), ou la documentation de la distribution Hadoop que vous utilisez. Par exemple, cette page (en anglais) liste certaines propriétés Hadoop par défaut.
Pour tirer parti de cette table des propriétés, consultez Configuration des propriétés réutilisables de Hadoop.
- Use Spark Properties : cochez la case Use Spark properties pour ouvrir la table des propriétés, puis ajoutez la propriété ou les propriétés spécifiques à la configuration Spark que vous souhaitez utiliser, par exemple, depuis le fichier spark-defaults.conf de votre cluster.
-
Lorsque la distribution à utiliser est Microsoft HDInsight, vous devez paramétrer la configuration de WebHCat configuration pour votre cluster HDInsight, la configuration de HDInsight configuration pour les identifiants de votre cluster HDInsight et la configuration de Window Azure Storage au lieu des paramètres mentionnés ci-dessus.
Paramètre Description WebHCat configuration
Saisissez l'adresse et les informations d'authentification du cluster Microsoft HDInsight à utiliser. Par exemple, l'adresse peut être nom_de_votre_cluster_hdinsight.azurehdinsight.net et les informations d'authentification peuvent être votre nom de compte Azure : ychen. Le Studio Talend utilise ce service pour soumettre le Job au cluster HDInsight.
Dans le champ Job result folder, saisissez l'emplacement où vous souhaitez stocker les résultats d'exécution du Job dans Azure Storage.
HDInsight configuration
- L'identifiant Username est celui défini lors de la création de votre cluster. Vous pouvez le trouver dans le panneau SSH + Cluster login, dans votre cluster.
- Le mot de passe Password est défini lors de la création de votre cluster HDInsight pour authentification dans ce cluster.
Windows Azure Storage configuration
Saisissez l'adresse et les informations d'authentification du compte Azure Storage ou ADLS Gen2 à utiliser. Dans cette configuration, vous ne définissez pas l'emplacement où lire ou écrire vos données métier, seulement où déployer votre Job.
Dans la liste déroulante Primary storage, sélectionnez le stockage à utiliser.
Si vous souhaitez sécuriser les connexion dans le stockage avec TLS, cochez la case use secure connection (TLS).
Dans le champ Container, saisissez le nom du conteneur à utiliser. Vous pouvez trouver les conteneurs disponibles dans le panneau Blob, dans le compte Azure Storage à utiliser.
Dans le champ Deployment Blob, saisissez l'emplacement où vous souhaitez stocker le Job et ses bibliothèques dépendantes dans le compte Azure Storage.
Dans le champ Hostname, saisissez l'endpoint du service du Blob primaire de votre compte Azure Storage, sans la partie https://. Vous pouvez trouver cet endpoint dans le panneau Properties de ce compte de stockage.
Dans le champ Username, saisissez le nom du compte Azure Storage à utiliser.
Dans le champ Password, saisissez la clé d'accès du compte Azure Storage à utiliser. Cette clé se trouve dans le panneau Access keys de ce compte de stockage.
- Si vous utilisez Cloudera V5.5 ou une version supérieure, vous pouvez cocher la case Use Cloudera Navigator pour permettre au Cloudera Navigator de votre distribution de visualiser le lignage de vos Jobs jusqu'au niveau des composants, notamment les modifications des schémas entre les composants.
Vous devez cliquer sur le bouton [...] pour ouvrir la fenêtre Cloudera Navigator Wizard et définir les paramètres suivants :
-
Username et Password : informations d'authentification utilisées pour vous connecter à votre Cloudera Navigator.
-
URL : saisissez l'emplacement du Cloudera Navigator auquel se connecter.
-
Metadata URL : saisissez l'emplacement de Navigator Metadata.
-
Client URL : laissez la valeur par défaut.
-
Autocommit : cochez cette case pour permettre à Cloudera Navigator de générer le lignage du Job courant à la fin de son exécution.
Comme cette option force le Cloudera Navigator à générer des lignages de toutes ses entités disponibles, comme les fichiers et répertoires HDFS, les requêtes Hive ou les scripts Pig, il n'est pas recommandé de l'utiliser dans un environnement de production, car elle ralentit le Job.
- Die on error : cochez cette case pour arrêter l'exécution de ce Job lorsque la connexion à Cloudera Navigator échoue. Sinon, laissez cette case décochée pour que votre Job continue à s'exécuter.
- Disable SSL : cochez cette case pour permettre à votre Job de se connecter à Cloudera Navigator sans processus de validation SSL.
Cette fonctionnalité est conçue pour simplifier les tests de vos Jobs mais il n'est pas recommandé de l'utiliser dans un cluster en production.
Une fois la configuration effectuée, cliquez sur Finish pour valider les paramètres.
-
-
-
Cliquez sur Finish pour valider vos modifications et fermer l'assistant.
La nouvelle connexion à Hadoop s'affiche dans le dossier Hadoop cluster de la vue Repository. Cette connexion ne contient pas de sous-dossier tant que vous ne créez pas d'élément dans cette distribution.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !