
Écrire des données dans un stockage de fichiers Cloud (S3)
Avant de commencer
-
Assurez-vous que votre utilisateur ou groupe d’utilisateurs dispose des autorisations appropriées pour accéder aux ressources d’Amazon S3.
Si vous ne disposez pas de ces autorisations, vous pouvez essayer une des options suivantes.- (recommandée) Demandez à l’administrateur qui gère votre compte Amazon de vous donner/de donner à votre utilisateur·rice les autorisations S3 appropriées.
- Implémentez votre politique d’accès en suivant la documentation Amazon si vous êtes autorisé(e) à le faire.
- (non recommandée) Joindre la politique AmazonS3FullAccess à votre groupe/votre utilisateur·rice via la console IAM. Cela vous permet de lire les ressources S3 et d’écrire dans ces ressources S3 sans restriction dans un bucket spécifique. Cependant, ceci est une solution rapide qui n’est pas recommandée par Talend.
Note InformationsRemarque : L’erreur par défaut qui s’affiche lorsque vous essayez d’accéder aux ressources S3 sans autorisation suffisante est Bad Gateway. -
Téléchargez le fichier : financial_transactions.avro.
- Créer un Moteur distant Gen2 et son profil d'exécution depuis Talend Management Console.
Le Moteur Cloud pour le design et son profil d'exécution correspondant sont embarqués par défaut dans Talend Management Console pour permettre aux utilisateurs et utilisatrices de prendre l'application en main rapidement, mais il est recommandé d'installer le Moteur distant Gen2 sécurisé pour le traitement avancé des données.
Procédure
-
Sélectionnez S3 connection dans la liste Connection type.
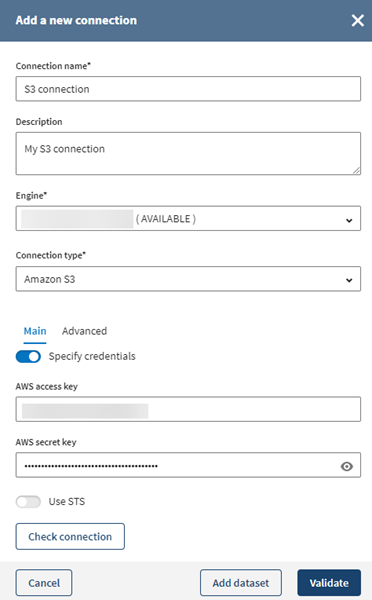
-
Cliquez sur View sample (Voir l'échantillon) pour vérifier que vos données sont valides et peuvent être prévisualisées.
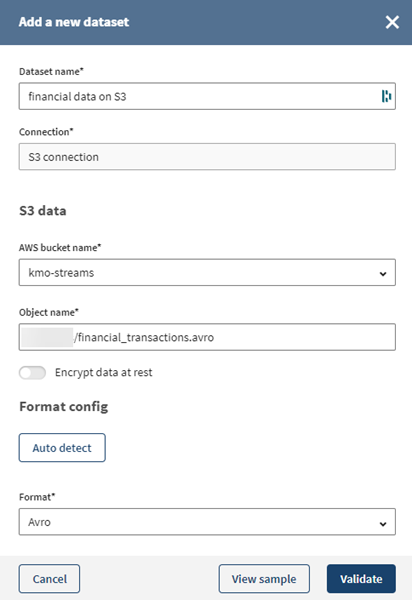
Résultats
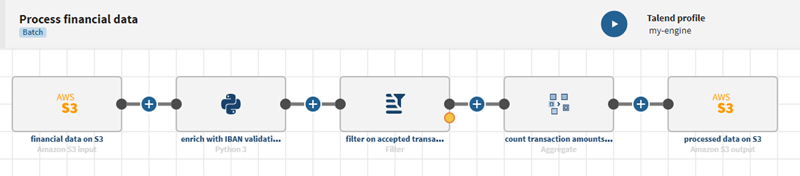
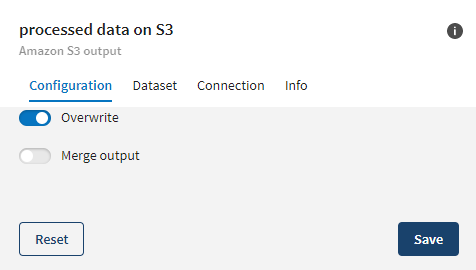
Une fois que votre pipeline est exécuté, les données mises à jour sont visibles dans le fichier situé sur Amazon S3.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !