
大型のルックアップテーブルを処理
この記事では、具体的なユースケースを示し、Studio Talendで問題を処理する方法について説明します。
このシナリオでは、テーブル内に数億のレコードを持つソーステーブルがあり、この入力データは、別のデータベースに同様に数億のレコードを持つテーブルからのデータをルックアップするために使用されます。ルックアップデータと結合されたソースデータは、ターゲットテーブルに挿入されるか、またはそこで更新されます。
前提条件
- ソーステーブルとルックアップテーブルには、結合条件に使用できる共通のカラムがあります。
- ソーステーブルとルックアップテーブルは、異なるRDBMシステム内にあります。
問題の説明
ソースデータをcustテーブルから読み込み、location_idカラムを使用してCUST_LOCATIONSテーブルをルックアップする単純なジョブを持っています。これはtMapで行われています。
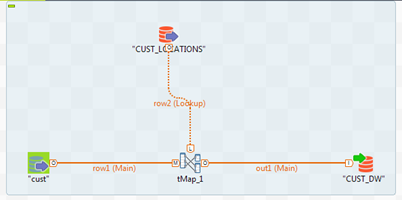
このジョブを実行すると、ルックアップデータ(7000万行)全体をメモリに読み込む途中でメモリ不足になります。このジョブはロードが小型の場合はうまくいきますが、ソーステーブルとルックアップテーブルに億単位のレコードがある場合には、非常に非効率的です。
ルックアップが大きい場合は、[Store] (保管)一時データをtrueに設定することを推奨します。
ですが、このシナリオではまだ十分ではありません。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。