
クラスターからのデータのインポート
HDFS (Hadoop File System)に保存されたデータにTalend Data Preparationインターフェイスから直接アクセスして、データセットの形でインポートします。
手順
-
[HDFS]を選択します。
[Add a HDFS dataset] (HDFSデータセットの追加)フォームが開きます。
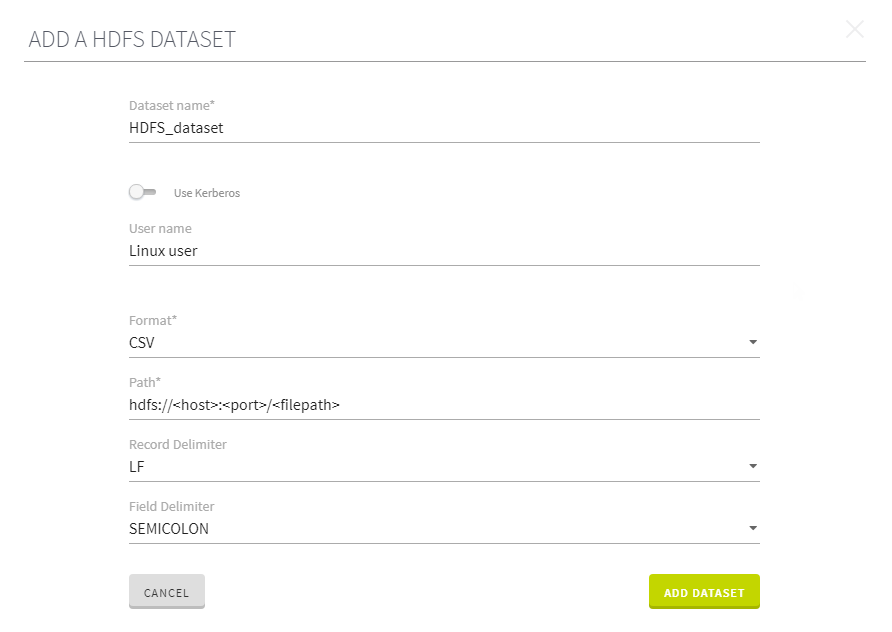
-
この例の場合は、[Use Kerberos] (Kerberosを使用)チェックボックスを未選択のままにしておきます。
Kerberosで認証する場合は、プリンシパルとkeytabファイルへのパスを入力します。
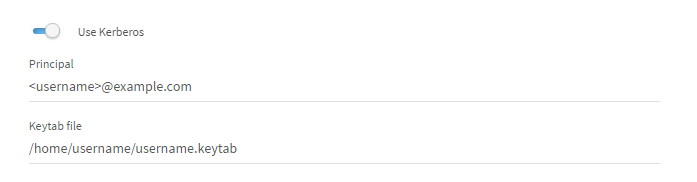
keytabファイルはSpark Job Serverによってアクセス可能でなければなりません。
これらのフィールドにデフォルト値が表示されるようにTalend Data Preparationを手動で設定できます。
タスクの結果
クラスターから抽出されたデータがグリッド内に開かれ、プレパレーションへの作業を開始できます。
データはクラスターに保存されたままの状態であり、Talend Data Preparationはサンプルのみをオンデマンドで取得します。
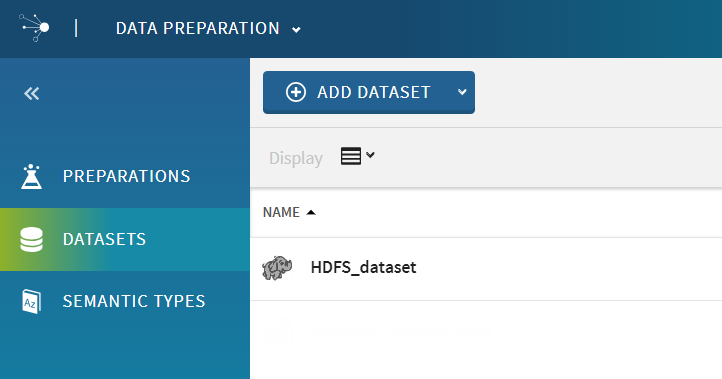
これで、データセットがアプリケーションのホームページの[Datasets] (データセット)ビューに表示されるようになります。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。