
AWSのDatabricksでS3に対してデータの書き込みと読み取りを実行
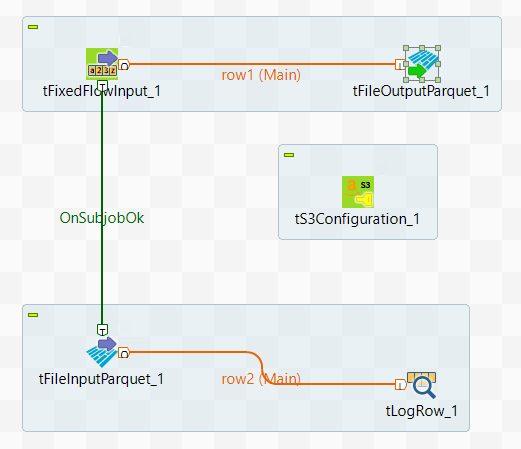
このシナリオでは、tS3Configurationを使ってSpark Batchジョブを作成し、Parquetコマンドを使ってデータをS3に書き込み、S3からデータを読み取ります。
このシナリオは、ビッグデータ関連Talend製品にのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご覧ください。
読み取られたサンプルデータは次のとおりです。
01;ychenこのデータには、ユーザー名とこのユーザーに配布されたID番号が含まれています。
サンプルデータはあくまでも例示用です。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。