
解析レベルごとに異なるルールタイプ
tStandardizeRowコンポーネントは、ANTLRではなく、 Talend で定義されたANTLR文法と詳細なルールに基づく基本ルールを使います。
3M PROJECT LAMP 7 LUMENS 32ML
A 5 LUMINES 5 LOW VANILLA 5L 5LIGHT 5 L DULUX L
54MLP FAC 32 ML次のような基本的な構文解析ルールの液体単位および液量を定義することによって開始できます: 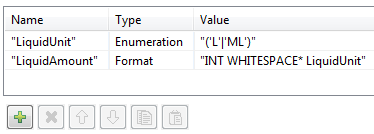
Studioの Profiling パースペクティブでテストすると、これらのルールが7 LUMENSから7 Lを抽出することがわかりますが、これは期待したものではありません。LUMENSという単語が2つのトークンに分割されることは望ましくありません。 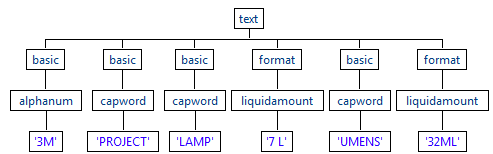
上記で定義した基本ルールはANTLRレクサールールであり、レクサールールは入力文字列のトークン化に使われます。ANTLRは、正規表現で使われる\bのような語境界記号を提供しません。入力文字列がトークンに分割される方法を定義するため、レクサールールを選択する時は注意が必要です。
このような問題は、次の2つの方法で解決できます。
最初のアプローチは、単語とその前に数値を一致させる別の基本的なルールを定義することです。この例では、金額ルールです: 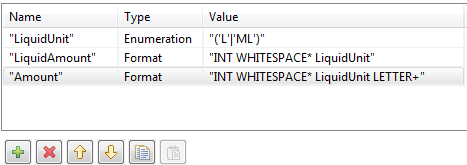
この基本ルールはレクサールールで、大文字で始まる[Format] (フォーマット)ルールです。Studioの Profiling パースペクティブでこのルールをテストすると、液体以外の量がこのルールに一致し、LiquidAmountルールは予想される文字のシーケンスにのみ一致することがわかります。 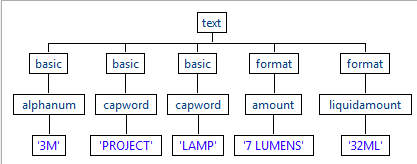
2番目のアプローチは、正規表現のような詳細なルールを使って、\bで語境界を定義します。レクサールールを使って、単語の前にある数値と一致する単語の金額をトークン化できます。次に、以下のように液体の量に一致する正規表現を使います。任意で数字の後にスペースが続き、その後にLまたはMLが続き、語境界で終了します。 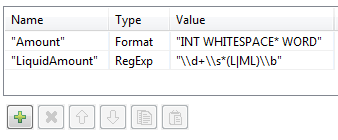
正規表現は、基本的なレクサールールによって作成されたトークンに適用されます。
3M PROJECT LAMP 7 LUMENS 32ML
<record>
<Amount>3M</Amount>
<Amount>7 LUMENS</Amount>
<LiquidAmount>32ML</LiquidAmount>
<UNMATCHED>
<CAPWORD>PROJECT</CAPWORD>
<CAPWORD>LAMP</CAPWORD>
</UNMATCHED>
</record>上記のルールの使用に関するジョブの例については、2つの解析レベルを使って非ストラクチャー化データから情報を抽出するをご覧ください。
これらの2つのアプローチを比較すると、最初のアプローチはANTLR文法のみを使い、正規表現に対して各トークンをチェックするために2番目の解析パスを必要とする2番目のソリューションよりも効率的です。ただし、正規表現は、熟練者がANTLRだけでは作成できない詳細なルールを作成するのに役立ちます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。